Appendix 1: Summary of the assembler
syntax.
Pseudo-instructions
.align
<abs-expr> , <abs-expr>
Pad the location counter to a storage boundary. The first
expression is the number of low-order zero bits the location counter must have
after advancement. For example .align 3
advances the location counter until it a multiple of 8. If the location counter
is already a multiple of 8, no change is needed. The second expression gives
the value to be stored in the padding bytes. It (and the comma) may be omitted.
If it is omitted, the padding bytes are zero.
.byte <expressions>
.byte expects zero or more expressions, separated by
commas. Each expression is assembled into the next byte.
.bss
Sets the current section to the bss section.
.comm <symbol’ , <length>
‘. comm’ declares a named common area in the bss section.
The linker will reserve space for it at link time.
.data
.data’ tells the assembler to assemble the following
statements onto the end of the data section.
.extern <symbol>
This pseudo instruction tells the assembler to declare the
given symbol as extern to the module being assembled.
.globl<symbol>
The indicated symbol will be declared as globally visible.
.lcomm<symbol>
This reserves space for a local symbol (not visible by
other modules) in the .bss section.
.line<number>
This indicates that the current offset in the text section
will be assigned to the program source line given by <number>. This ends
up in the debugging information.
.long <number>
Initializes a 4 byte location to the given number.
.text
Sets the current section to the text section.
Syntax
1.
Immediate operands are preceded by ‘$’; (Intel ‘push 4’
is « pushl $4»).
2.
Register operands are preceded by ‘%’.
3.
Absolute (as opposed to PC relative) jump/call operands
are prefixed by ‘*’.
4.
Intel syntax use the opposite order for source and
destination operands. Intel ‘add eax, 4’ is addl $4, %eax.
5.
The size of memory operands is determined from the last
character of the opcode name. Opcode suffixes of ‘b’, ‘w’, and ‘l’ specify byte
(8-bit), word (16-bit), and long (32-bit) memory references. Intel syntax
accomplishes this by prefixes memory operands (NOT the opcodes themselves) with
‘byte ptr’, ‘word ptr’, and ‘dword ptr’. Thus, Intel assembler mov al, byte ptr <foo> is movb <foo>, %al.
Opcode naming
Opcode names are suffixed with one-character modifiers,
which specify the size of operands. The letters ‘b’, ‘w’, and ‘l’ specify byte,
word, and long operands. If no suffix is specified by an instruction and it
contains no memory operands then lcc’s assembler tries to fill in the missing
suffix based on the destination register operand (the last one by convention).
Thus,
mov %ax, %bx
is equivalent to
movw %ax, %bx
also,
mov $1, %bx
is equivalent to
movw $1, %bx
Almost all opcodes have the same names than Intel format.
There are a few exceptions. The sign extend and zero extend instructions need
two sizes to specify them. They need a size to sign/zero extend FROM and a size
to zero extend TO. This is accomplished by using two opcode suffixes.
Base names for sign extend and zero extend are ‘movs...’
and ‘movz...’ (‘movsx’ and ‘movzx’ in Intel syntax). The opcode suffixes are
tacked on to this base name, the FROM suffix before the TO suffix. Thus,
movsbl %al, %edx
is:
move sign extend FROM %al TO %edx.
Possible suffixes, thus, are ‘bl’ (from byte to long), ‘bw’
(from byte to word), and ‘wl’ (from
word to long).
Memory references
An Intel syntax indirect memory reference of the form
<section>:[<base> + <index>*<scale>
+ <disp>]
is translated into the syntax
<section>:<disp>(<base>, <index>,
<scale>)
where
<base> and <index> are the optional 32-bit
base and index registers, <disp> is the optional displacement, and
<scale>, taking the values 1, 2, 4, and 8, multiplies <index> to
calculate the address of the operand.
If no <scale> is specified, <scale> is taken
to be 1. <section> specifies the optional section register for the memory
operand, and may override the default section register (see a Pentium manual
for section register defaults).
Note that section overrides in MUST have be preceded by a
‘%’.
Here are some examples of Intel and lcc style memory
references:
lcc: -4(%ebp), Intel: [ebp - 4]’
<base> is %ebp; <disp> is -4. <section>
is missing, and the default section is used (‘%ss’ for addressing with ‘%ebp’
as the base register). <index>, <scale> are both missing.
lcc: foo(,%eax,4) Intel:
[foo + eax*4]
<index> is ‘%eax’ (scaled by a <scale> 4);
<disp> is ‘foo’. All other fields are missing. The section register here
defaults to ‘%ds’.
lcc: foo(,1); Intel [foo]
This uses the value pointed to by foo as a memory operand.
Note that <base> and <index> are both missing, but there is only
ONE ,. This is a syntactic exception.
lcc: %gs:foo; Intel gs:foo
This selects the contents of the variable ‘foo’ with
section register <section> being ‘%gs’.
Absolute (as opposed to PC relative) call and jump operands must be prefixed with ‘*’. If no ‘*’ is specified, lcc always chooses PC relative addressing for jump/call labels. Any instruction that has a memory operand MUST specify its size (byte, word, or long) with an opcode suffix (‘b’, ‘w’, or ‘l’, respectively).
Comments are introduced by two “;;” starting in the first column of a line.
Data types used by the processor
The processor supports the following data types:
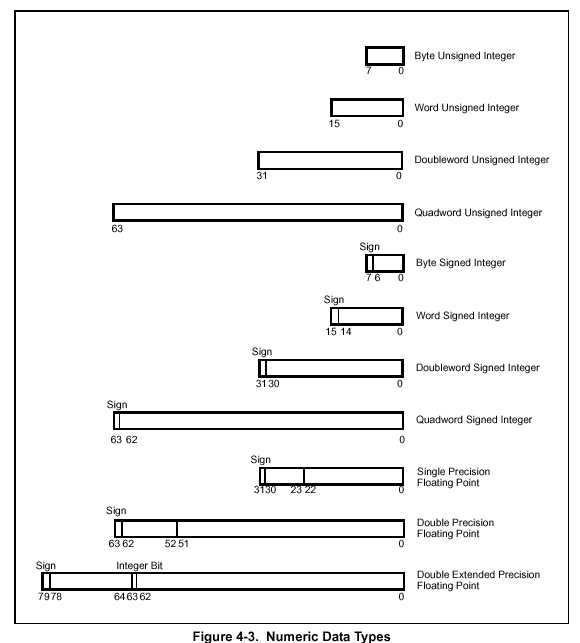
The lcc-win32 compiler uses those types with the following correspondence between the C types and the processor types:
|
Machine type |
C Language type |
|
Byte |
Signed/unsigned char |
|
Word |
Signed/unsigned short |
|
Double word |
Signed/unsigned int |
|
Quad word |
Long long |
|
Double quad word |
No match as a unit. |
|
Single precision floating point |
Float |
|
Double precision floating point |
Double |
|
Double extended precision floating point |
No match. |
Note that the lcc-win32 assembler is a user-mode assembler, and all instructions that run only in privilege level zero aren’t included in the assembler tables. You should recompile the assembler with those instructions if you are writing an operating system module.
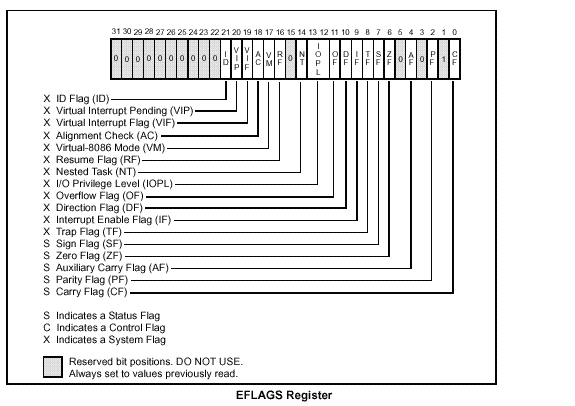
The flags registers:
The 32-bit EFLAGS register contains information about the state of the processor and the results of some of the instructions (carry flag, overflow flag) and others.
The 32-bit
MXCSR register contains control and status information for SSE and SSE2 SIMD
floating-point operations. This register contains the flag and mask bits for
the SIMD floating-point exceptions, the rounding control field for SIMD
floating-point operations, the flush-to-zero flag that provides a means of
controlling underflow conditions on SIMD floating-point operations, and the
denormals-are-zeros flag that controls how SIMD floating-point instructions
handle denormal source operands.
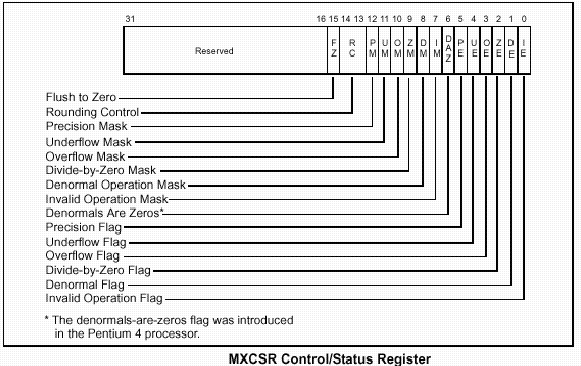
The contents of this register can be loaded from memory with the LDMXCSR and FXRSTOR instructions and stored in memory with the STMXCSR and FXSAVE instructions.
The conversion instructions
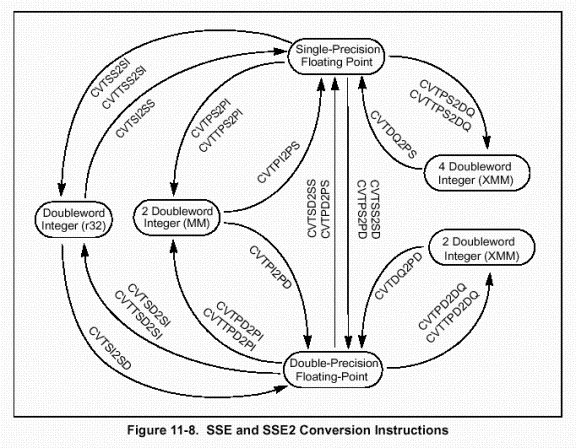
Instruction
Table
This is an adaptation of the documentation provided by Intel Corporation (http://www.intel.com) with the necessary modifications done for the assembler of lcc-win32, specifically, the inversing of the operands.
|
Opcode |
Description |
Syntax |
Detailed description |
||||||||||||||||||||||||
|
aaa |
ASCII
Adjust After Addition |
aaa |
Adjusts the sum of two
unpacked BCD values to create an unpacked BCD result. The AL register is the
implied source and destination operand for this instruction. The AAA
instruction is only useful when it follows an ADD instruction that adds
(binary addition) two unpacked BCD values and stores a byte result in the AL
register. The AAA instruction then adjusts the contents of the AL register to
contain the correct 1-digit unpacked BCD result. If the addition produces a
decimal carry, the AH register is incremented by 1, and the CF and AF flags
are set. If there was no decimal carry, the CF and AF flags are cleared and
the AH register is unchanged. In either case, bits 4 through 7 of the AL
register are cleared to 0. |
||||||||||||||||||||||||
|
aad |
ASCII Adjust AX Before Division |
|
Adjusts two
unpacked BCD digits (the least-significant digit in the AL register and the
most-significant digit in the AH register) so that a division operation
performed on the resul t will yield a correct unpacked BCD value. The AAD
instruction is only useful when it precedes a DIV instruction that divides
(binary division) the adjusted value in the AX register by an unpacked BCD value. The AAD instruction sets
the value in the AL register to (AL + (10 * AH)), and then clears the AH
register to 00H. The value in the AX register is then equal to the binary
equivalent of the original unpacked two-digit (base 10) number in registers
AH and AL. The generalized version of this instruction allows adjustment of
two unpacked digits of any number base (see the “Operation” section below),
by setting the imm8 byte to the selected number base (for example, 08H
for octal, 0AH for decimal, or 0CH for base 12 numbers). The AAD mnemonic is
interpreted by all assemblers to mean adjust ASCII (base 10) values. To
adjust values in another number base, the instruction must be hand coded in
machine code (D5 imm8). |
||||||||||||||||||||||||
|
aam |
ASCII Adjust AX After Multiply |
|
Adjusts the result of the multiplication of two unpacked BCD
values to create a pair of unpacked (base 10) BCD values. The AX register is
the implied source and destination operand for this instruction. The AAM
instruction is only useful when it follows an MUL instruction that multi-plies (binary multiplication) two unpacked BCD values and stores a
word result in the AX register. The AAM instruction then adjusts the contents
of the AX register to contain the correct 2-digit unpacked (base 10) BCD
result. The generalized version of this instruction allows adjustment of the
contents of the AX to create two unpacked digits of any number base (see the
“Operation” section below). Here, the imm8 byte is set to the selected number
base (for example, 08H for octal, 0AH for decimal, or 0CH for base 12
numbers). The AAM mnemonic is interpreted by all assemblers to mean adjust to
ASCII (base 10) values. To adjust to values in another number base, the
instruction must be hand coded in machine code (D4 imm8). |
||||||||||||||||||||||||
|
aas |
ASCII Adjust AL After Subtraction |
|
Adjusts the result of the subtraction of two unpacked BCD values
to create a unpacked BCD result. The AL register is the implied source and
destination operand for this instruction. The AAS instruction is only useful
when it follows a SUB instruction that subtracts (binary subtrac-tion) one
unpacked BCD value from another and stores a byte result in the AL register.
The AAA instruction then adjusts the contents of the AL register to contain
the correct 1-digit unpacked BCD result. If the subtraction produced a decimal
carry, the AH register is decremented by 1, and the CF and AF flags are set.
If no decimal carry occurred, the CF and AF flags are cleared, and the AH register is unchanged. In either case, the AL register is left
with its top nibble set to 0. |
||||||||||||||||||||||||
|
adc |
Add with Carry |
|
Adds the destination operand (second operand), the source
operand (first operand), and the carry (CF) flag and stores the result in the
destination operand. The destination operand can be a register or a memory
location; the source operand can be an immediate, a register, or a memory
location. (However, two memory operands cannot be used in one instruction.)
The state of the CF flag represents a carry from a previous addition. When an
immediate value is used as an operand, it is sign-extended to the length of
the destination operand format. The ADC instruction does not distinguish
between signed or unsigned operands. Instead, the processor evaluates the
result for both data types and sets the OF and CF flags to indicate a carry in the signed or unsigned result, respectively. The SF flag
indicates the sign of the signed result. The ADC instruction is usually
executed as part of a multibyte or multiword addition in which an ADD
instruction is followed by an ADC instruction. |
||||||||||||||||||||||||
|
add |
Add |
|
Adds the second operand (destination operand) and the first
operand (source operand) and stores the result in the destination operand.
The destination operand can be a register or a memory location; the source
operand can be an immediate, a register, or a memory location. (However, two
memory operands cannot be used in one instruction.) When an immediate value
is used as an operand, it is sign-extended to the length of the destination
operand format. The ADD instruction does not distinguish between signed or
unsigned operands. Instead, the processor evaluates the result for both data
types and sets the OF and CF flags to indicate a carry in the signed or
unsigned result, respectively. The SF flag indicates the sign of the signed
result. |
||||||||||||||||||||||||
|
addpd |
Add Packed Double-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a
SIMD add of the two packed double-precision floating-point values from the
source operand (first operand) and the destination operand (second operand),
and stores the packed double precision floating-point results in the
destination operand. The source operand can be an XMM register or a 128-bit
memory location. The destination operand is an XMM register. |
||||||||||||||||||||||||
|
addps |
Add Packed Single-Precision Floating-Point Values. SSE/SSE2 Instruction |
|
Performs a
SIMD add of the four packed single-precision floating-point values from the
source operand (first operand) and the destination operand (first operand),
and stores the packed single-precision floating-point results in the
destination operand. The source operand can be an XMM register or a 128-bit
memory location. The destination operand is an XMM register. |
||||||||||||||||||||||||
|
addsd |
Add Scalar Double-Precision Floating-Point Values SSE/SSE2
Instruction |
|
Adds the
low double-precision floating-point values from the source operand (first operand)
and the destination operand (second operand), and stores the double-precision
floating-point result in the destination operand. The source operand can be
an XMM register or a 64-bit memory location. The destination operand is an
XMM register. The high quad word of the destination operand remains
unchanged. |
||||||||||||||||||||||||
|
addss |
Add Scalar Single-Precision Floating-Point Values SSE/SSE2
Instruction |
|
Adds the
low single-precision floating-point values from the source operand (first
operand) and the destination operand (second operand), and stores the
single-precision floating-point result in the destination operand. The source
operand can be an XMM register or a 32-bit memory location. The destination
operand is an XMM register. The three high-order double words of the
destination operand remain unchanged. |
||||||||||||||||||||||||
|
and |
Logical AND |
|
Performs a bitwise AND operation on the destination (second) and
source (first) operands and stores the result in the destination operand
location. The source operand can be an immediate, a register, or a memory
location; the destination operand can be a register or a memory location.
(However, two memory operands cannot be used in one instruction.) Each bit of
the result is set to 1 if both corresponding bits of the first and second
operands are 1; otherwise, it is set to 0. |
||||||||||||||||||||||||
|
andnpd |
Bitwise Logical AND NOT of Packed Double-Precision
Floating-Point Values. SSE/SSE2
Instruction |
|
Inverts the
bits of the two packed double-precision floating-point values in the
destination operand (second operand), performs a bit wise logical AND of the
two packed double-precision floating-point values in the source operand
(first operand) and the temporary inverted result, and stores the result in
the destination operand. The source operand can be an XMM register or a 128-bit
memory location. The destination operand is an XMM register. If the
memory location is not aligned in a 16-byte boundary the processor traps. |
||||||||||||||||||||||||
|
andnps |
Bitwise Logical AND NOT of Packed Single-Precision
Floating-Point Values SSE/SSE2
Instruction |
|
Inverts the
bits of the four packed single-precision floating-point values in the
destination operand (second operand), performs a bit wise logical AND of the
four packed single-precision floating-point values in the source operand
(first operand) and the temporary inverted result, and stores the result in
the destination operand. The source operand can be an XMM register or a
128-bit memory location. The destination operand is an XMM register. If the
memory location is not aligned in a 16-byte boundary the processor traps. |
||||||||||||||||||||||||
|
bound |
Check Array Index Against Bounds |
|
Determines if the second operand (array index) is within the
bounds of an array specified the first operand (bounds operand). The array
index is a signed integer located in a register. The bounds operand is a
memory location that contains a pair of signed double word-integers (when the
operand-size attribute is 32) or a pair of signed word-integers (when the
operand-size attribute is 16). The first double word (or word) is the lower
bound of the array and the second double word (or word) is the upper bound of
the array. The array index must be greater than or equal to the lower bound
and less than or equal to the upper bound plus the operand size in bytes. If
the index is not within bounds, a BOUND range exceeded exception (#BR) is
signaled. (When a this exception is generated, the saved return instruction
pointer points to the BOUND instruction.) The bounds limit data structure
(two words or double words containing the lower and upper limits of the
array) is usually placed just before the array itself, making the limits
addressable via a constant offset from the beginning of the array. Because
the address of the array already will be present in a register, this practice
avoids extra bus cycles to obtain the effective address of the array bounds. |
||||||||||||||||||||||||
|
bsf |
Bit Scan Forward |
|
Searches the source operand (first operand) for the least
significant set bit (1 bit). If a least significant 1 bit is found, its bit
index is stored in the destination operand (second operand). The source
operand can be a register or a memory location; the destination operand is a
register. The bit index is an unsigned offset from bit 0 of the source
operand. If the contents source operand is 0, the contents of the destination
operand are undefined. |
||||||||||||||||||||||||
|
bsr |
Bit Scan Reverse |
|
Searches the source operand (first operand) for the most
significant set bit (1 bit). If a most significant 1 bit is found, its bit
index is stored in the destination operand (first operand). The source
operand can be a register or a memory location; the destination operand is a
register. The bit index is an unsigned offset from bit 0 of the source
operand. If the contents source operand is 0, the contents of the destination
operand are undefined. |
||||||||||||||||||||||||
|
bswap |
Byte Swap |
|
Reverses the byte order of a 32-bit (destination) register: bits
0 through 7 are swapped with bits 24 through 31, and bits 8 through 15 are
swapped with bits 16 through 23. This instruction is provided for converting
little-endian values to big-endian format and vice versa. To swap bytes in a
word value (16-bit register), use the XCHG instruction. When the BSWAP
instruction references a 16-bit register, the result is undefined. |
||||||||||||||||||||||||
|
bt |
Bit Test |
|
Selects the bit in a bit string (specified
with the second operand, called the bit base) at the bit-position designated
by the bit offset operand (first operand) and stores the value of the bit in
the CF flag. The bit base operand can be a register or a memory location; the
bit offset operand can be a register or an immediate value. If the bit base
operand specifies a register, the instruction takes the modulo 16 or 32
(depending on the register size) of the bit offset operand, allowing any bit
position to be selected in a 16- or 32-bit register, respectively (see Figure
3-1). If the bit base operand specifies a memory location, it represents the
address of the byte in memory that contains the bit base (bit 0 of the
specified byte) of the bit string (see Figure 3-2). The offset operand then
selects a bit position within the range -2 31 to
2 31 -1
for a register offset and 0 to 31 for an immediate offset. Some assemblers
support immediate bit offsets larger than 31 by using the immediate bit
offset field in combination with the displacement field of the memory
operand. In this case, the low-order 3 or 5 bits (3 for 16-bit operands, 5
for 32-bit operands) of the immediate bit offset are stored in the immediate
bit offset field, and the high-order bits are shifted and combined with the
byte displacement in the addressing mode by the assembler. The processor will
ignore the high order bits if they are not zero. When accessing a bit in
memory, the processor may access 4 bytes starting from the memory address for
a 32-bit operand size, using by the following relationship: Effective Address + (4 *(BitOffset DIV 32)) Or,
it may access 2 bytes starting from the memory address for a 16-bit operand,
using this rela-tionship: Effective Address + (2 *(BitOffset DIV 16)) It may do
so even when only a single byte needs to be accessed to reach the given bit.
When using this bit addressing mechanism, software should avoid referencing
areas of memory close to address space holes. In particular, it should avoid
references to memory-mapped I/O registers. Instead, software should use the
MOV instructions to load from or store to these addresses, and use the
register form of these instructions to manipulate the data. |
||||||||||||||||||||||||
|
btc |
Bit Test and Complement |
|
Selects the bit in a bit string (specified with the second
operand, called the bit base) at the bit-position designated by the bit
offset operand (first operand), stores the value of the bit in the CF flag,
and complements the selected bit in the bit string. The bit base operand can
be a register or a memory location; the bit offset operand can be a register
or an immediate value. If the bit base operand specifies a register, the
instruction takes the modulo 16 or 32 (depending on the register size) of the
bit offset operand, allowing any bit position to be selected in a 16- or
32-bit register, respectively (see Figure 3-1). If the bit base operand
specifies a memory location, it represents the address of the byte in memory
that contains the bit base (bit 0 of the specified byte) of the bit string
(see Figure 3-2). The offset operand then selects a bit position within the
range −2 31 to 2 31 −1 for a register offset and 0 to 31 for an
immediate offset. |
||||||||||||||||||||||||
|
btr |
Bit Test and Reset |
|
Selects the bit in a bit string (specified with the second
operand, called the bit base) at the bit-position designated by the bit
offset operand (first operand), stores the value of the bit in the CF flag,
and clears the selected bit in the bit string to 0. The bit base operand can
be a register or a memory location; the bit offset operand can be a register
or an immediate value. If the bit base operand specifies a register, the
instruction takes the modulo 16 or 32 (depending on the register size) of the
bit offset operand, allowing any bit position to be selected in a 16- or
32-bit register, respectively. If the bit base operand specifies a memory
location, it represents the address of the byte in memory that contains the
bit base (bit 0 of the specified byte) of the bit string (see Figure 3-2).
The offset operand then selects a bit position within the range −2**31
to 2**31 −1 for a register offset and 0 to 31 for an immediate offset. |
||||||||||||||||||||||||
|
bts |
Bit Test and Set |
|
Selects the bit in a bit string (specified with the second
operand, called the bit base) at the bit-position designated by the bit
offset operand (first operand), stores the value of the bit in the CF flag,
and sets the selected bit in the bit string to 1. The bit base operand can be
a register or a memory location; the bit-offset operand can be a register or
an immediate value. If the bit base operand specifies a register, the
instruction takes the modulo 16 or 32 (depending on the register size) of the
bit offset operand, allowing any bit position to be selected in a 16- or
32-bit register, respectively (see Figure 3-1). If the bit base operand
specifies a memory location, it represents the address of the byte in memory
that contains the bit base (bit 0 of the specified byte) of the bit string
(see Figure 3-2). The offset operand then selects a bit position within the
range −2 31 to 2 31 −1 for a register offset and 0 to 31 for an
immediate offset. |
||||||||||||||||||||||||
|
call |
Call Procedure |
|
Saves
procedure linking information on the stack and branches to the procedure
(called procedure) specified with the destination (target) operand. The
target operand specifies the address of the first instruction in the called
procedure. This operand can be an immediate value, a general-purpose register,
or a memory location. This instruction can be used to execute four different
types of calls: • Near
call—A call to a procedure within the current code segment (the segment
currently pointed to by the CS register), sometimes referred to as an
intrasegment call. • Far
call—A call to a procedure located in a different segment than the current
code segment, sometimes referred to as an intersegment call. • Inter-privilege-level
far call—A far call to a procedure in a segment at a different privilege
level than that of the currently executing program or procedure. • Task
switch—A call to a procedure located in a different task. The latter two call types
(inter-privilege-level call and task switch) can only be executed in
protected mode. |
||||||||||||||||||||||||
|
cbw/cwde |
Convert Byte to Word/Convert Word to Doubleword |
|
Double the size of the source operand by means of sign extension
The CBW (convert byte to word) instruction copies the sign (bit 7) in the
source operand into every bit in the AH register. The CWDE (convert word to
doubleword) instruction copies the sign (bit 15) of the word in the AX
register into the higher 16 bits of the EAX register. The CBW and CWDE
mnemonics reference the same opcode. The CBW instruction is intended for use
when the operand-size attribute is 16 and the CWDE instruction for when the
operand-size attribute is 32. Lcc forces the operand size to 16 when CBW is
used. The CWDE instruction is different from the CWD (convert word to double)
instruction. The CWD instruction uses the DX:AX register pair as a
destination operand; whereas, the CWDE instruction uses the EAX register as a
destination. |
||||||||||||||||||||||||
|
cdq/cltd |
Convert Word to Double word/Convert double word to Quad word |
|
Doubles the size of the operand in register AX or EAX (depending
on the operand size) by means of sign extension and stores the result in
registers DX:AX or EDX:EAX, respectively. The CWD instruction copies the sign
(bit 15) of the value in the AX register into every bit position in the DX
register. The CDQ instruction copies the sign (bit 31) of the value in the
EAX register into every bit position in the EDX register. The CWD instruction
can be used to produce a double word dividend from a word before a word
division, and the CDQ instruction can be used to produce a quad word dividend
from a double word before double word division. The CWD and CDQ mnemonics
reference the same opcode. The CWD instruction is intended for use when the
operand-size attribute is 16 and the CDQ instruction for when the
operand-size attribute is 32. |
||||||||||||||||||||||||
|
clc |
Clear Carry Flag |
|
Clears the CF flag in the EFLAGS register. |
||||||||||||||||||||||||
|
cld |
Clear Direction Flag |
|
Clears the DF flag in the EFLAGS register. When the DF flag is
set to 0, string operations increment the index registers (ESI and/or EDI). |
||||||||||||||||||||||||
|
cmc |
Complement carry flag |
|
Complements
the CF flag in the EFLAGS register. |
||||||||||||||||||||||||
|
cmova |
Move
if above (CF=0 and ZF=0) |
|
The CMOVcc instructions check the state of one or more of the
status flags in the EFLAGS register (CF, OF, PF, SF, and ZF) and perform a
move operation if the flags are in a specified state (or condition). A
condition code (cc) is associated with each instruction to indicate the
condition being tested for. If the condition is not satisfied, a move is not
performed and execution continues with the instruction following the CMOVcc
instruction. These instructions can move a 16- or 32-bit value from memory to
a general-purpose register or from one general-purpose register to another.
Conditional moves of 8-bit register operands are not supported. The conditions for each CMOVcc mnemonic is given in the
description column of the table in the left. The terms “less” and “greater”
are used for comparisons of signed integers and the terms “above” and “below”
are used for unsigned integers. Because a particular state of the status flags can sometimes be
interpreted in two ways, two mnemonics are defined for some opcodes. For
example, the CMOVA (conditional move if above) instruction and the CMOVNBE
(conditional move if not below or equal) instruction are alternate mnemonics
for the opcode 0F 47H. |
||||||||||||||||||||||||
|
cmovae |
Move if
above (CF=0 and ZF=0) |
|
|||||||||||||||||||||||||
|
cmovb |
Move if
below (CF=1) |
|
|||||||||||||||||||||||||
|
cmovbe |
Move if
below or equal (CF=1 or ZF=1) |
|
|||||||||||||||||||||||||
|
cmovc |
Move if
carry (CF=1) |
|
|||||||||||||||||||||||||
|
cmove |
Move if
equal (ZF=1) |
|
|||||||||||||||||||||||||
|
cmovg |
Move if
greater (ZF=0 and SF=OF) |
|
|||||||||||||||||||||||||
|
cmovge |
Move if
greater or equal (SF=OF) |
|
|||||||||||||||||||||||||
|
cmovl |
Move if
less (SF<>OF) |
|
|||||||||||||||||||||||||
|
cmovle |
Move if
less or equal (ZF=1 or SF<>OF) |
|
|||||||||||||||||||||||||
|
cmovna |
Move if
not above (CF=1 or ZF=1) |
|
|||||||||||||||||||||||||
|
cmovnae |
Move if
not above or equal (CF=1) |
|
|||||||||||||||||||||||||
|
cmovnb |
Move if
not below (CF=0) |
|
|||||||||||||||||||||||||
|
cmovnbe |
Move if
not below or equal (CF=0 and ZF=0) |
|
|||||||||||||||||||||||||
|
cmovnc |
Move if
not carry (CF=0) |
|
|||||||||||||||||||||||||
|
cmovne |
Move if
not equal (ZF=0) |
|
|||||||||||||||||||||||||
|
cmovng |
Move if
not greater (ZF=1 or SF<>OF) |
|
|||||||||||||||||||||||||
|
cmovnge |
Move if
not greater or equal (SF<>OF) |
|
|||||||||||||||||||||||||
|
cmovnl |
Move if
not less (SF=OF) |
|
|||||||||||||||||||||||||
|
cmovno |
Move if
not overflow (OF=0) |
|
|||||||||||||||||||||||||
|
cmovnp |
Move if
not parity (PF=0) |
|
|||||||||||||||||||||||||
|
cmovns |
Move if
not sign (SF=0) |
|
|||||||||||||||||||||||||
|
cmovnz |
Move if
not zero (ZF=0) |
|
|||||||||||||||||||||||||
|
cmovo |
Move if
overflow (OF=0) |
|
|||||||||||||||||||||||||
|
cmovp |
Move if
parity (PF=1) |
|
|||||||||||||||||||||||||
|
cmovpe |
Move if
parity even (PF=1) |
|
|||||||||||||||||||||||||
|
cmovpo |
Move if
parity odd (PF=0) |
|
|||||||||||||||||||||||||
|
cmovs |
Move if
sign (SF=1) |
|
|||||||||||||||||||||||||
|
cmovz |
Move if
zero (ZF=1) |
|
|||||||||||||||||||||||||
|
cmp |
Compare Two Operands |
|
Compares the source operand with the other source operand and
sets the status flags in the EFLAGS register according to the results. The
comparison is performed by subtracting the first operand from the second
operand and then setting the status flags in the same manner as the SUB
instruction. When an immediate value is used as an operand, it is
sign-extended to the length of the first operand. The CMP instruction is typically
used in conjunction with a conditional jump (Jcc), condition move (CMOVcc),
or SETcc instruction. The condition codes used by the Jcc, CMOVcc, and SETcc
instructions are based on the results of a CMP instruction. |
||||||||||||||||||||||||
|
cmpeqpd |
Compare Packed Double-Precision Floating-Point Values for
equality. SSE/SSE2
Instruction |
|
Performs a
SIMD compare of the two packed double-precision floating-point values in the
source operand (first operand) and the destination operand (first operand)
and returns the results of the comparison to the destination operand. The
comparison predicate operand specifies the type of comparison performed on
each of the pairs of packed values. The result of each comparison is a quad
word mask of all 1s (comparison true) or all 0s (comparison false). The
source operand can be an XMM register or a 128-bit memory location. The
destination operand is an XMM register. The
unordered relationship is true when at least one of the two source operands
being compared is a NaN or in an undefined format. The ordered relationship
is true when neither source operand is a NaN or in an undefined format. A
subsequent computational instruction that uses the mask result in the
destination operand as an input operand will not generate an exception,
because a mask of all 0s corresponds to a floating-point value of +0.0 and a
mask of all 1s corresponds to a QNaN. Note that the processor does not
implement the greater-than, greater-than-or-equal, not greater than, and
not-greater-than-or-equal relations. These comparisons can be made either by
using the inverse relationship (that is, use the “not-less-than-or-equal” to
make a “greater-than” comparison) or by using software emulation. When using
software emulation, the program must swap the operands (copying registers when
necessary to protect the data that will now be in the destination), and then
perform the compare using a different predicate. |
||||||||||||||||||||||||
|
cmplepd |
Compare Packed Double-Precision Floating-Point Values for less
than or equal SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpltpd |
Compare Packed Double-Precision Floating-Point Values for less
than. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpneqpd |
Compare Packed Double-Precision Floating-Point Values for not
equal. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpnlepd |
Compare Packed Double-Precision Floating-Point Values for less or
equal. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpnltpd |
Compare Packed Double-Precision Floating-Point Values for less
than. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpordpd |
Compare Packed Double-Precision Floating-Point Values with
ordered comparison. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpunordpd |
Compare Packed Double-Precision Floating-Point Values with
unordered comparison. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpeqsd |
Compare Packed Single-Precision Floating-Point Values for
equality. SSE/SSE2
Instruction |
|
Performs a SIMD
compare of the four packed single-precision floating-point values in the
source operand (first operand) and the destination operand (second operand)
and returns the results of the comparison to the destination operand. The
comparison predicate specifies the
type of comparison performed on each of the pairs of packed values. The
result of each comparison is a doubleword mask of all 1s (comparison true) or
all 0s (comparison false). The source operand can be an XMM register or a
128-bit memory location. The destination operand is an XMM register. The unordered
relationship is true when at least one of the two source operands being
compared is a NaN or in an undefined format. The ordered relationship is true
when neither source operand is a NaN or in an undefined format. A subsequent
computational instruction that uses the mask result in the destination
operand as an input operand will not generate a fault, because a mask of all
0s corresponds to a floating-point value of +0.0 and a mask of all 1s
corresponds to a QNaN. Some of the comparisons listed in Table 3-5 (such as
the greater-than, greater-than-or-equal, not-greater- than, and
not-greater-than-or-equal relations) can be made only through software
emulation. For these
comparisons the program must swap the operands (copying registers when necessary
to protect the data that will now be in the destination), and then perform
the compare using a different predicate. |
||||||||||||||||||||||||
|
cmplesd |
Compare Packed Single-Precision Floating-Point Values for less
or equal. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpltsd |
Compare Packed Single-Precision Floating-Point Values for less
than. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpordsd |
Compare Packed Single-Precision Floating-Point Values with
ordered comparison. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmpunordsd |
Compare Packed Single-Precision Floating-Point Values with unordered
comparison. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
cmps |
Compare String Operands |
|
Compares the byte, word, or double word specified with the first
source operand with the byte, word, or double word specified with the second
source operand and sets the status flags in the EFLAGS register according to
the results. Both the source operands are located in memory. The address of
the first source operand is read from either the DS:ESI or the DS:SI
registers (depending on the address-size attribute of the instruction, 32 or
16, respectively). The address of the second source operand is read from
either the ES:EDI or the ES:DI registers (again depending on the address-size
attribute of the instruction). The DS segment may be overridden with a
segment override prefix, but the ES segment cannot be overridden. At the
assembly-code level, two forms of this instruction are allowed: the
“explicit-operands” form and the “no-operands” form. The explicit-operands
form (specified with the CMPS mnemonic) allows the two source operands to be
specified explicitly. Here, the source operands should be symbols that
indicate the size and location of the source values. This explicit-operands
form is provided to allow documentation; however, note that the documentation
provided by this form can be misleading. That is, the source operand symbols
must specify the correct type (size) of the operands (bytes, words, or
doublewords), but they do not have to specify the correct loca-tion. The
locations of the source operands are always specified by the DS:(E)SI and
ES:(E)DI registers, which must be loaded correctly before the compare string
instruction is executed. The no-operands form provides “short forms” of the
byte, word, and doubleword versions of the CMPS instructions. Here also the
DS:(E)SI and ES:(E)DI registers are assumed by the processor to specify the
location of the source operands. The size of the source operands is selected
with the mnemonic: CMPSB (byte comparison), CMPSW (word comparison), or CMPSD
(double-word comparison). After the comparison, the (E)SI and (E)DI registers are
incremented or decremented automatically according to the setting of the DF
flag in the EFLAGS register. (If the DF flag is 0, the (E)SI and (E)DI
register are incremented; if the DF flag is 1, the (E)SI and (E)DI registers
are decremented.) The registers are incremented or decremented by 1 for byte
operations, by 2 for word operations, or by 4 for double word operations. The CMPS, CMPSB, CMPSW, and CMPSD instructions can be preceded
by the REP prefix for block comparisons of ECX bytes, words, or double words.
More often, however, these instruc-tions will be used in a LOOP construct
that takes some action based on the setting of the status flags before the
next comparison is made. See “REP/REPE/REPZ/REPNE /REPNZ—Repeat String
Operation Prefix” in this chapter for a description of the REP prefix. |
||||||||||||||||||||||||
|
cmpxchg |
Compare and Exchange |
|
Compares the value in the AL, AX, or EAX register (depending on
the size of the operand) with the second operand (destination operand). If
the two values are equal, the second operand (source operand) is loaded into
the destination operand. Otherwise, the destination operand is loaded into
the AL, AX, or EAX register. This instruction can be used with a LOCK prefix to allow the
instruction to be executed atomically. To simplify the interface to the
processor’s bus, the destination operand receives a write cycle without
regard to the result of the comparison. The destination operand is written
back if the comparison fails; otherwise, the source operand is written into
the destination. (The processor never produces a locked read without also
producing a locked write.) |
||||||||||||||||||||||||
|
cmpxchg8b |
Compare and Exchange 8 Bytes. Introduced with the Pentium processor. |
|
Compares the 64-bit
value in EDX:EAX with the operand (destination operand). If the values are
equal, the 64-bit value in ECX:EBX is stored in the destination operand.
Otherwise, the value in the destination operand is loaded into EDX:EAX. The
destination operand is an 8-byte memory location. For the EDX:EAX and ECX:EBX
register pairs, EDX and ECX contain the high-order 32 bits and EAX and EBX
contain the low-order 32 bits of a 64-bit value. This instruction can
be used with a LOCK prefix to allow the instruction to be executed
atomically. To simplify
the interface to the processor’s bus, the destination operand receives a
write cycle without regard to the result of the comparison. The destination
operand is written back if the comparison fails; otherwise, the source
operand is written into the destination. (The processor never produces a
locked read without also producing a locked write.) |
||||||||||||||||||||||||
|
comisd |
Compare Scalar Ordered Double-Precision Floating-Point Values and Set EFLAGS. SSE/SSE2
Instruction |
|
Compares the
double-precision floating-point values in the low quad words of source
operand 1 (second operand) and source operand 2 (first operand), and sets the
ZF, PF, and CF flags in the EFLAGS register according to the result
(unordered, greater than, less than, or equal). The OF, SF and AF flags in
the EFLAGS register are set to 0. The unordered result is returned if either source operand is a
NaN (QNaN or SNaN). Source operand 1 is an
XMM register; source operand 2 can be an XMM register or a 64 bit memory
location. The COMISD instruction
differs from the UCOMISD instruction in that it signals a SIMD floating-point
invalid operation exception (#I) when a source operand is either a QNaN or
SNaN. The UCOMISD instruction signals an invalid numeric exception only if a
source operand is an SNaN. The EFLAGS
register is not updated if an unmasked SIMD floating-point exception is
generated. |
||||||||||||||||||||||||
|
comiss |
Compare Scalar Ordered Single-Precision Floating-Point Values and Set EFLAGS. SSE/SSE2
Instruction |
|
Compares the
single-precision floating-point values in the low double words of source operand
1 (second operand) and the source operand 2 (first operand), and sets the ZF,
PF, and CF flags in the EFLAGS register according to the result (unordered,
greater than, less than, or equal). The OF, SF and AF flags in the EFLAGS
register are set to 0. The unordered result is returned if either source
operand is a NaN (QNaN or SNaN). Source operand 1 is an
XMM register; source operand 2 can be an XMM register or a 32-bit memory
location. The COMISS instruction
differs from the UCOMISS instruction in that it signals a SIMD floating-point
invalid operation exception (#I) when a source operand is either a QNaN or
SNaN. The UCOMISS instruction signals an invalid numeric exception only if a
source operand is an SNaN. The EFLAGS register is
not updated if an unmasked SIMD floating-point exception is generated. |
||||||||||||||||||||||||
|
cpuid |
CPU Identification |
|
Provides processor identification information in registers EAX,
EBX, ECX, and EDX. This information identifies Intel as the vendor, gives the
family, model, and stepping of processor, feature information, and cache
information. An input value loaded into the EAX register deter-mines what
information is returned, as shown in the following table
|
||||||||||||||||||||||||
|
cvtdq2pd |
Convert Packed Double word Integers to Packed Double-Precision
Floating-Point Values SSE/SSE2
Instruction |
|
Converts
two packed signed double word integers in the source operand (first operand)
to two packed double-precision floating-point values in the destination
operand (second operand). The source operand can be an XMM register or a
64-bit memory location. The destination operand is an XMM register. When the
source operand is an XMM register, the packed integers are located in the low
quad word of the register. |
||||||||||||||||||||||||
|
cvtdq2ps |
Convert Packed Double word Integers to Packed Single-Precision
Floating-Point Values. SSE/SSE2
Instruction |
|
Converts
four packed signed double word integers in the source operand (first operand)
to four packed single-precision floating-point values in the destination
operand (second operand). The source operand can be an XMM register or a
128-bit memory location. The destination operand is an XMM register. When a
conversion is inexact, rounding is performed according to the rounding control
bits in the MXCSR register. |
||||||||||||||||||||||||
|
cvtpd2dq |
Convert Packed Double-Precision Floating-Point Values to Packed
Double word Integers. SSE/SSE2
Instruction |
|
Converts two packed
double-precision floating-point values in the source operand (first operand)
to two packed signed double word integers in the destination operand (second
operand). The source operand can
be an XMM register or a 128-bit memory location. The destination operand is
an XMM register. The result is stored in the low quad word of the destination
operand and the high quad word is cleared to all 0s. When a
conversion is inexact, the value returned is rounded according to the
rounding control bits in the MXCSR register. If a converted result is larger
than the maximum signed double word integer, the indefinite integer value
(80000000H) is returned. |
||||||||||||||||||||||||
|
cvtpd2pi |
Convert Packed Double-Precision Floating-Point Values to Packed
Double word Integers. SSE/SSE2
Instruction Mmx
Instruction |
|
Converts two packed
double-precision floating-point values in the source operand (first operand)
to two packed signed double word integers in the destination operand (second
operand). The source operand can
be an XMM register or a 128-bit memory location. The destination operand is
an MMX register. When a conversion is
inexact, the value returned is rounded according to the rounding control bits
in the MXCSR register. If a converted result is larger than the maximum
signed double word integer, the indefinite integer value (80000000H) is
returned. This instruction
causes a transition from x87 FPU to MMX technology operation (that is, the
x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to
all 0s [valid]). If this instruction is executed while an x87 FPU
floating-point exception is pending, the exception is handled before the
CVTPD2PI instruction is executed. |
||||||||||||||||||||||||
|
cvtpd2ps |
Convert Packed Double-Precision Floating-Point Values to Packed
Single-Precision Floating-Point Values. SSE/SSE2 Instruction |
|
Converts two packed
double-precision floating-point values in the source operand (first operand)
to two packed single-precision floating-point values in the destination
operand (second operand). The source operand can be an XMM register or a
128-bit memory location. The destination operand is an XMM register. The
result is stored in the low quad word of the destination operand, and the high
quad word is cleared to all 0s. When a conversion is inexact, the value
returned is rounded according to the rounding control bits in the MXCSR
register. |
||||||||||||||||||||||||
|
cvtpi2pd |
Convert Packed Doubleword Integers to Packed Double-Precision
Floating-Point Values. SSE/SSE2
Instruction Mmx
Instruction |
|
Converts two packed
signed double word integers in the source operand (second operand) to two
packed double-precision floating-point values in the destination operand
(first operand). The source operand can be an MMX register or a 64-bit memory
location. The destination operand is an XMM register. This instruction causes
a transition from x87 FPU to MMX technology operation (that is, the x87 FPU
top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all 0s
[valid]). If this instruction is executed while an x87 FPU floating-point
exception is pending, the exception is handled before the CVTPI2PD
instruction is executed. |
||||||||||||||||||||||||
|
cvtpi2ps |
Convert Packed Double word Integers to Packed Single-Precision
Floating-Point Values. SSE/SSE2
Instruction Mmx
Instruction |
|
Converts two packed
signed double word integers in the source operand (first operand) to two
packed single-precision floating-point values in the destination operand
(second operand). The source operand can be an MMX register or a 64-bit
memory location. The destination operand is an XMM register. The results are
stored in the low quad word of the destination operand, and the high quad
word remains unchanged. This instruction causes a transition from x87 FPU to
MMX technology operation (that is, the x87 FPU top-of-stack
pointer is set to 0 and the x87 FPU tag word is set to all 0s [valid]). If
this instruction is executed while an x87 FPU floating-point exception is
pending, the exception is handled before the CVTPI2PS instruction is
executed. |
||||||||||||||||||||||||
|
cvtps2dq |
Convert Packed Single-Precision Floating-Point Values to Packed
Double word Integers. SSE/SSE2
Instruction |
|
Converts four packed
single-precision floating-point values in the source operand (first operand)
to four packed signed double word integers in the destination operand (second
operand). The source operand can be an XMM register or a 128-bit memory
location. The destination operand is an XMM register. When a conversion is
inexact, the value returned is rounded according to the rounding control bits
in the MXCSR register. If a converted result is larger than the maximum
signed double word integer, the indefinite integer value (80000000H) is
returned. |
||||||||||||||||||||||||
|
cvtps2pd |
Convert Packed Single-Precision Floating-Point Values to Packed
Double-Precision Floating-Point Values SSE/SSE2
Instruction |
|
Converts two packed
single-precision floating-point values in the source operand (first operand)
to two packed double-precision floating-point values in the destination
operand (second operand). The source operand can be an XMM register or a
64-bit memory location. The destination operand is an XMM register. When the
source operand is an XMM register, the packed single-precision floating-point
values are contained in the low quad word of the register. |
||||||||||||||||||||||||
|
cvtps2pi |
Convert Packed Single-Precision Floating-Point Values to Packed
Double word Integers SSE/SSE2
Instruction Mmx
Instruction |
|
Converts two packed
single-precision floating-point values in the source operand (first operand)
to two packed signed double word integers in the destination operand (second
operand). The source operand can be an XMM register or a 128-bit memory
location. The destination operand is an MMX register. When the source operand
is an XMM register, the two single-precision floating-point values are
contained in the low quad word of the register. When a conversion is
inexact, the value returned is rounded according to the rounding control bits
in the MXCSR register. If a converted result is larger than the maximum
signed double word integer, the indefinite integer value (80000000H) is
returned. This instruction
causes a transition from x87 FPU to MMX technology operation (that is, the
x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to
all 0s [valid]). If this instruction is executed while an x87 FPU
floating-point exception is pending, the exception is handled before the
CVTPS2PI instruction is executed. |
||||||||||||||||||||||||
|
cvtsd2si |
Convert Scalar Double-Precision Floating-Point Value to Double
word Integer SSE/SSE2
Instruction |
|
Converts a
double-precision floating-point value in the source operand (first operand)
to a signed double word integer in the destination operand (second operand).
The source operand can be an XMM register or a 64-bit memory location. The
destination operand is a general-purpose register. When the source operand is
an XMM register, the double-precision floating-point value is contained in
the low quad word of the register. When a conversion is
inexact, the value returned is rounded according to the rounding control bits
in the MXCSR register. If a converted result is larger than the maximum
signed double word integer, the indefinite integer value (80000000H) is
returned. |
||||||||||||||||||||||||
|
cvtsd2ss |
Convert Scalar Double-Precision Floating-Point Value to Scalar
Single-Precision Floating-Point Value SSE/SSE2
Instruction |
|
Converts a
double-precision floating-point value in the source operand (first operand)
to a single-precision floating-point value in the destination operand (second
operand). The source operand can be an XMM register or a 64-bit memory
location. The destination operand is an XMM register. When the source operand
is an XMM register, the double-precision floating-point value is contained in
the low quad word of the register. The result is stored in the low double
word of the destination operand, and the upper 3 double words are left
unchanged. When the conversion is inexact, the value returned is rounded
according to the rounding control bits in the MXCSR register. |
||||||||||||||||||||||||
|
cvtsi2sd |
Convert Doubleword Integer to Scalar Double-Precision
Floating-Point Value SSE/SSE2
Instruction |
|
Converts a signed
double word integer in the source operand (first operand) to a
double-precision floating-point value in the destination operand (second
operand). The source operand can be a general-purpose register or a 32-bit
memory location. The destination operand is an XMM register. The result is
stored in the low quad word of the destination operand, and the high
quad-word left unchanged. |
||||||||||||||||||||||||
|
cvtsi2ss |
Convert Doubleword Integer to Scalar Single-Precision
Floating-Point Value SSE/SSE2
Instruction |
|
Converts a signed
double word integer in the source operand (first operand) to a
single-precision floating-point value in the destination operand (second
operand). The source operand can be a general-purpose register or a 32-bit
memory location. The destination operand is an XMM register. The result is
stored in the low double word of the destination operand, and the upper three doublewords are
left unchanged. When a conversion is inexact, the value returned is rounded
according to the rounding control bits in the MXCSR register. |
||||||||||||||||||||||||
|
cvtss2sd |
Convert Scalar Single-Precision Floating-Point Value to Scalar
Double-Precision Floating-Point Value. SSE/SSE2
Instruction |
|
Converts a
single-precision floating-point value in the source operand (first operand)
to a double-precision floating-point value in the destination operand (second
operand). The source operand can be an XMM register or a 32-bit memory location.
The destination operand is an XMM register. When the source operand is an XMM
register, the single-precision floating-point value is contained in
the low double word of the register. The result is stored in the low quad
word of the destination operand, and the high quad word is left unchanged. |
||||||||||||||||||||||||
|
cvtss2si |
Convert Scalar Single-Precision Floating-Point Value to Double
word Integer. SSE/SSE2
Instruction |
|
Converts a
single-precision floating-point value in the source operand (first operand)
to a signed double word integer in the destination operand (first operand).
The source operand can be an XMM register or a 32-bit memory location. The
destination operand is a general-purpose register. When the source operand is
an XMM register, the single-precision floating-point value is contained in the
low double word of the register. When a conversion is
inexact, the value returned is rounded according to the rounding control bits
in the MXCSR register. If a converted result is larger than the maximum
signed double word integer, the indefinite integer value (80000000H) is
returned. |
||||||||||||||||||||||||
|
cvttpd2pi |
Convert with Truncation Packed Double-Precision Floating-Point
Values to Packed Doubleword Integers. SSE/SSE2
Instruction Mmx
Instruction |
|
Converts two packed
double-precision floating-point values in the source operand (first operand)
to two packed signed double word integers in the destination operand (second
operand). The source operand can
be an XMM register or a 128-bit memory location. The destination operand is
an MMX register. When a conversion is inexact, a truncated (round toward
zero) result is returned. If a converted result is larger than the maximum
signed double word integer, the indefinite integer value (80000000H) is
returned. This instruction
causes a transition from x87 FPU to MMX technology operation (that is, the
x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to
all 0s [valid]). If this instruction is executed while an x87 FPU
floating-point exception is pending, the exception is handled before the
CVTTPD2PI instruction is executed. |
||||||||||||||||||||||||
|
cvttpd2dq |
Convert with Truncation Packed Double-Precision Floating-Point
Values to Packed Doubleword Integers. SSE/SSE2
Instruction Mmx
Instruction |
|
Converts two packed
double-precision floating-point values in the source operand (first operand)
to two packed signed double word integers in the destination operand (second
operand). The source operand can
be an XMM register or a 128-bit memory location. The destination operand is
an XMM register. The result is stored in the low quad word of the destination
operand and the high quad word is cleared to all 0s. When a conversion is
inexact, a truncated (round toward zero) result is returned. If a converted
result is larger than the maximum-signed double word integer, the indefinite
integer value (80000000H) is returned. |
||||||||||||||||||||||||
|
cvttps2dq |
Convert with Truncation Packed Single-Precision Floating-Point
Values to Packed Double word Integers. SSE/SSE2
Instruction |
|
Converts four packed
single-precision floating-point values in the source operand (first operand)
to four packed signed double word integers in the destination operand (second
operand). The source operand can
be an XMM register or a 128-bit memory location. The destination operand is
an XMM register. When a conversion is inexact, a truncated (round toward
zero) result is returned. If a converted result is larger than the maximum
signed double word integer, the indefinite integer value (80000000H) is
returned. |
||||||||||||||||||||||||
|
cvttps2pi |
Convert with Truncation Packed Single-Precision Floating-Point
Values to Packed Double word Integers. SSE/SSE2
Instruction Mmx
Instruction |
|
Converts two packed
single-precision floating-point values in the source operand (first operand)
to two packed signed double word integers in the destination operand (second
operand). The source operand can
be an XMM register or a 64-bit memory location. The destination operand is an
MMX register. When the source operand is an XMM register, the two
single-precision floating-point values are contained in the low quad word of
the register. When a conversion is
inexact, a truncated (round toward zero) result is returned. If a converted
result is larger than the maximum-signed double word integer, the indefinite
integer value (80000000H) is returned. This instruction
causes a transition from x87 FPU to MMX technology operation (that is, the
x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to
all 0s [valid]). If this instruction is executed while an x87 FPU
floating-point exception is pending, the exception is handled before the
CVTTPS2PI instruction is executed. |
||||||||||||||||||||||||
|
cvtsd2si |
Convert with Truncation Scalar Double-Precision Floating-Point
Value to Signed Double word Integer SSE/SSE2
Instruction |
|
Converts a
double-precision floating-point value in the source operand (first operand)
to a signed double word integer in the destination operand (second operand).
The source operand can be an XMM register or a 64-bit memory location. The
destination operand is a general-purpose register. When the
source operand is an XMM register, the double-precision floating-point value
is contained in the low quad word of the register. When a conversion is
inexact, a truncated (round toward zero) result is returned. If a converted
result is larger than the maximum signed double word integer, the indefinite
integer value (80000000H) is returned. |
||||||||||||||||||||||||
|
cvtss2si |
Convert with Truncation Scalar Single-Precision Floating-Point
Value to Double word Integer. SSE/SSE2
Instruction |
|
Converts a
single-precision floating-point value in the source operand (first operand)
to a signed double word integer in the destination operand (second operand).
The source operand can be an XMM register or a 32-bit memory location. The
destination operand is a general-purpose register. When the source operand is
an XMM register, the single-precision floating-point value is contained in
the low double word of the register. When a conversion is inexact, a
truncated (round toward zero) result is returned. If a converted result is
larger than the maximum signed double word integer, the indefinite integer
value (80000000H) is returned. |
||||||||||||||||||||||||
|
cwd |
Convert Word to Double word or Convert Double word to Quad word |
|
Doubles the size of the operand in register AX or EAX (depending
on the operand size) by means of sign extension and stores the result in
registers DX:AX or EDX:EAX, respectively. The CWD instruction copies the sign
(bit 15) of the value in the AX register into every bit position in the DX
register The CDQ instruction copies the sign (bit 31) of the value in the EAX
register into every bit position in the EDX register. The CWD instruction can
be used to produce a double word dividend from a word before a word division,
and the CDQ instruction can be used to produce a quad word dividend from a
double word before double word division. The CWD and CDQ mnemonics reference
the same opcode. The CWD instruction is intended for use when the
operand-size attribute is 16 and the CDQ instruction for when the
operand-size attribute is 32. Some assemblers may force the operand size to
16 when CWD is used and to 32 when CDQ is used. Others may treat these
mnemonics as synonyms (CWD/CDQ) and use the current setting of the
operand-size attribute to determine the size of values to be converted,
regardless of the mnemonic used. |
||||||||||||||||||||||||
|
daa |
Decimal Adjust AL after Addition |
|
Adjusts the sum of two packed BCD values to create a packed BCD
result. The AL register is the implied source and destination operand. The
DAA instruction is only useful when it follows an ADD instruction that adds
(binary addition) two 2-digit, packed BCD values and stores a byte result in
the AL register. The DAA instruction then adjusts the contents of the AL
register to contain the correct 2-digit, packed BCD result. If a decimal
carry is detected, the CF and AF flags are set accordingly. |
||||||||||||||||||||||||
|
das |
Decimal Adjust AL after Subtraction |
|
Adjusts the result of the subtraction of two packed BCD values
to create a packed BCD result. The AL register is the implied source and
destination operand. The DAS instruction is only useful when it follows a SUB
instruction that subtracts (binary subtraction) one 2-digit, packed BCD value from another and stores a byte result in the AL
register. The DAS instruction then adjusts the contents of the AL register to
contain the correct 2-digit, packed BCD result. If a decimal borrow is
detected, the CF and AF flags are set accordingly. |
||||||||||||||||||||||||
|
dec |
Decrement by 1 |
|
Subtracts 1 from the destination operand, while preserving the
state of the CF flag. The destination operand can be a register or a memory
location. This instruction allows a loop counter to be updated without
disturbing the CF flag. (To perform a decrement operation that updates the CF
flag, use a SUB instruction with an immediate operand of 1.) |
||||||||||||||||||||||||
|
div |
Unsigned Divide |
|
Divides (unsigned) the value in the AX register, DX:AX register
pair, or EDX:EAX register pair (dividend) by the source operand (divisor) and
stores the result in the AX (AH:AL), DX:AX, or EDX:EAX registers. The source
operand can be a general-purpose register or a memory location. The action of
this instruction depends on the operand size, as shown in the following
table:
|
||||||||||||||||||||||||
|
divpd |
Divide Packed Double-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a
SIMD divide of the two packed double-precision floating-point values in the
destination operand (second operand) by the two packed double-precision
floating-point values in the source operand (first operand), and stores the
packed double precision floating-point results in the destination operand.
The source operand can be an XMM register or a 128-bit memory location. The
destination operand is an XMM register. |
||||||||||||||||||||||||
|
divps |
Divide Packed Single-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a
SIMD divide of the two packed single-precision floating-point values in the
destination operand (second operand) by the two packed single-precision
floating-point values in the source operand (first operand), and stores the
packed single-precision floating-point results in the destination operand.
The source operand can be an XMM register or a 128-bit memory location. The
destination operand is an XMM register. |
||||||||||||||||||||||||
|
divsd |
Divide Scalar Double-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Divides the low
double-precision floating-point value in the destination operand (second
operand) by the low double-precision floating-point value in the source
operand (first operand), and stores the double precision floating-point
result in the destination operand. The source operand can be an
XMM register or a 64-bit memory location. The destination operand is an XMM register.
The high quad word of the destination operand remains unchanged. |
||||||||||||||||||||||||
|
divss |
Divide Scalar Single-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Divides the low
single-precision floating-point value in the destination operand (second
operand) by the low single-precision floating-point value in the source
operand (first operand), and stores the single-precision floating-point
result in the destination operand. The source operand can be an XMM register
or a 32-bit memory location. The destination operand is an XMM register. The
three high-order double words of the destination operand remain unchanged. |
||||||||||||||||||||||||
|
emms |
Empty MMX State Mmx Instruction |
|
Sets the values of all the tags in the x87 FPU tag word to empty
(all 1s). This operation marks the x87 FPU data registers (which are aliased
to the MMX registers) as available for use by x87 FPU floating-point
instructions. All other MMX instructions (other than the EMMS instruction)
set all the tags in x87 FPU tag word to valid (all 0s). The EMMS instruction
must be used to clear the MMX state at the end of all MMX routines and before
calling other procedures or subroutines that may execute x87 floating-point
instructions. If a floating-point instruction loads one of the registers in
the x87 FPU data register stack before the x87 FPU tag word has been reset by
the EMMS instruction, an x87 floating-point stack over-flow can occur that
will result in an x87 floating-point exception or incorrect result. |
||||||||||||||||||||||||
|
enter |
Make Stack Frame for Procedure Parameters |
|
Creates a stack frame for a procedure. The second operand (size
operand) specifies the size of the stack frame (that is, the number of bytes
of dynamic storage allocated on the stack for the proce-dure). The first
operand (nesting level operand) gives the lexical nesting level (0 to 31) of
the procedure. The nesting level determines the number of stack frame
pointers that are copied into the “display area” of the new stack frame from
the preceding frame. Both of these operands are immediate values. The stack-size attribute determines whether the BP (16 bits) or
EBP (32 bits) register specifies the current frame pointer and whether SP (16
bits) or ESP (32 bits) specifies the stack pointer. The ENTER and companion
LEAVE instructions are provided to support block structured languages. The
ENTER instruction (when used) is typically the first instruction in a
procedure and is used to set up a new stack frame for a procedure. The LEAVE
instruction is then used at the end of the procedure (just before the RET
instruction) to release the stack frame. If the nesting level is 0, the processor pushes the frame
pointer from the EBP register onto the stack, copies the current stack
pointer from the ESP register into the EBP register, and loads the ESP
register with the current stack-pointer value minus the value in the size
operand. For nesting levels of 1 or greater, the processor pushes additional
frame pointers on the stack before adjusting the stack pointer. These
additional frame pointers provide the called procedure with access points to
other nested frames on the stack. |
||||||||||||||||||||||||
|
f2xm1 |
Compute 2**x –1 |
|
Computes the exponential value of 2 to the power of the source
operand minus 1. The source operand is located in register ST(0) and the
result is also stored in ST(0). The value of the source operand must lie in
the range –1.0 to +1.0. If the source value is outside this range, the result
is undefined. |
||||||||||||||||||||||||
|
fabs |
Absolute Value |
|
Clears the sign bit of ST(0) to create the absolute value of the
operand. |
||||||||||||||||||||||||
|
fadd fiadd |
Add |
|
Adds the destination and source operands and stores the sum in
the destination location. The destination operand is always an FPU register;
the source operand can be a register or a memory location. Source operands in
memory can be in single-real, double real, word-integer, or short-integer formats. The no-operand version of the instruction adds the contents of
the ST(0) register to the ST(1) register. The one-operand version adds the
contents of a memory location (either a real or an integer value) to the
contents of the ST(0) register. The two-operand version, adds the contents of
the ST(0) register to the ST(i) register or vice versa. The value in ST(0)
can be doubled by coding: FADD ST(0), ST(0); The FADDP instructions perform the additional operation of
popping the FPU register stack after storing the result. To pop the register
stack, the processor marks the ST(0) register as empty and increments the
stack pointer (TOP) by 1. (The no-operand version of the floating-point add
instructions always results in the register stack being popped. In some
assemblers, the mnemonic for this instruction is FADD rather than FADDP.) The FIADD instructions convert an integer source operand to
extended-real format before performing the addition. When the sum of two
operands with opposite signs is 0, the result is +0, except for the round
toward −∞mode,
in which case the result is −0. When the source operand is an integer
0, it is treated as a +0. When both operand are infinities of the same sign, the result is
∞of
the expected sign. If both operands are infinities of opposite signs, an
invalid-operation exception is generated. |
||||||||||||||||||||||||
|
fbld |
Load Binary Coded Decimal |
|
Converts the BCD source operand into extended-real format and
pushes the value onto the FPU stack. The source operand is loaded without
rounding errors. The sign of the source operand is preserved, including that
of −0. The packed BCD digits are assumed to be in the range 0 through
9; the instruction does not check for invalid digits (AH through FH).
Attempting to load an invalid encoding produces an undefined result. |
||||||||||||||||||||||||
|
fbstp |
Store BCD Integer and Pop |
|
Converts the value in the ST(0) register to an 18-digit packed
BCD integer, stores the result in the destination operand, and pops the
register stack. If the source value is a non-integral value, it is rounded to
an integer value, according to rounding mode specified by the RC field of the
FPU control word. To pop the register stack, the processor marks the ST(0)
register as empty and increments the stack pointer (TOP) by 1. The destination operand specifies the address where the first byte
destination value is to be stored. The BCD value (including its sign bit)
requires 10 bytes of space in memory. |
||||||||||||||||||||||||
|
fchs |
Change sign |
|
Complements the sign bit of ST(0). This operation changes a
positive value into a negative value of equal magnitude or vice versa. |
||||||||||||||||||||||||
|
fclex |
Clear Exceptions |
|
Clears the floating-point exception flags (PE, UE, OE, ZE, DE,
and IE), the exception summary status flag (ES), the stack fault flag (SF),
and the busy flag (B) in the FPU status word. The FCLEX instruction checks
for and handles any pending unmasked floating-point exceptions before
clearing the exception flags; the FNCLEX instruction does not. |
||||||||||||||||||||||||
|
fcmovb fcmovbe fcmove fcmovnb fcmovne fcmovnu fcmovu |
Floating-Point Conditional Move |
|
Tests the status flags in the EFLAGS register and moves the
source operand (first operand) to the destination operand (second operand) if
the given test condition is true. The source operand is always in the ST(i)
register and the destination operand is always ST(0). The FCMOVcc
instructions are useful for optimizing small IF constructions. They also help
eliminate branching overhead for IF operations and the possibility of branch
mispredictions by the processor. A processor may not support the FCMOVcc instructions. Software
can check if the FCMOVcc instructions are supported by checking the
processor’s feature information with the CPUID instruction (see
“COMISS—Compare Scalar Ordered Single-Precision Floating-Point Values and Set
EFLAGS” in this chapter). If both the CMOV and FPU feature bits are set, the
FCMOVcc instructions are supported. |
||||||||||||||||||||||||
|
fcom fcomp fcompp |
Compare Real |
|
Compares the contents of register ST(0) and source value and
sets condition code flags C0, C2, and C3 in the FPU status word according to
the results (see the table below). The source operand can be a data register
or a memory location. If no source operand is given, the value in ST(0) is
compared with the value in ST(1). The sign of zero is ignored, so that –0.0 ←+0.0. This instruction checks the class of the numbers being compared
(see “FXAM—Examine” in this table). If either operand is a NaN or is in an
unsupported format, an invalid-arithmetic-operand exception (#IA) is raised
and, if the exception is masked, the condition flags are set to “unordered.”
If the invalid-arithmetic-operand exception is unmasked, the condition code
flags are not set. The FCOMP instruction pops the register stack following the
comparison operation and the FCOMPP instruction pops the register stack twice
following the comparison operation. To pop the register stack, the processor
marks the ST(0) register as empty and increments the stack pointer (TOP) by
1.
|
||||||||||||||||||||||||
|
fcomi fcomip |
|
|
Compares the contents of register ST(0) and ST(i) and sets the
status flags ZF, PF, and CF in the EFLAGS register according to the results
(see the table below). The sign of zero is ignored for comparisons, so that
–0.0 ←+0.0. See the table above for the results of C0,C2,C3 |
||||||||||||||||||||||||
|
fcoml |
|
|
|
||||||||||||||||||||||||
|
fcompl |
|
|
|
||||||||||||||||||||||||
|
fcomps |
|
|
|
||||||||||||||||||||||||
|
fcoms |
|
|
|
||||||||||||||||||||||||
|
fcos |
Cosine |
|
Computes the cosine of the source operand in register ST(0) and
stores the result in ST(0). The source operand must be given in radians and must
be within the range −2 63 to +2 63 . |
||||||||||||||||||||||||
|
fdecstp |
Decrement Stack-Top Pointer |
|
Subtracts one from the TOP field of the FPU status word
(decrements the top-of-stack pointer). If the TOP field contains a 0, it is set to 7. The effect of
this instruction is to rotate the stack by one position. The contents of the
FPU data registers and tag register are not affected. |
||||||||||||||||||||||||
|
fdiv fidiv |
|
|
Divides the destination operand by the source operand and stores
the result in the destination location. The destination operand (dividend) is
always in an FPU register; the source operand (divisor) can be a register or
a memory location. Source operands in memory can be in single-real,
double-real, word-integer, or short-integer formats. The no-operand version of the instruction divides the contents
of the ST(1) register by the contents of the ST(0) register. The one-operand
version divides the contents of the ST(0) register by the contents of a
memory location (either a real or an integer value). The two-operand version,
divides the contents of the ST(0) register by the contents of the ST(i)
register or vice versa. The FDIVP instructions perform the additional operation of
popping the FPU register stack after storing the result. To pop the register
stack, the processor marks the ST(0) register as empty and increments the
stack pointer (TOP) by 1. The no-operand version of the floating-point divide
instructions always results in the register stack being popped. In some
assemblers, the mnemonic for this instruction is FDIV rather than FDIVP. The FIDIV instructions convert an integer source operand to
extended-real format before performing the division. When the source operand
is an integer 0, it is treated as a +0. If an unmasked divide-by-zero
exception (#Z) is generated, no result is stored; if the exception is masked,
an ∞of
the appropriate sign is stored in the destination operand.. |
||||||||||||||||||||||||
|
fdivr fdivrl fdivrp fdivrs |
Reverse Divide |
|
Divides the source operand by the destination operand and stores
the result in the destination location. The destination operand (divisor) is
always in an FPU register; the source operand (dividend) can be a register or
a memory location. Source operands in memory can be in single-real, double
real, word-integer, or short-integer formats. These instructions perform the
reverse operations of the FDIV, FDIVP, and FIDIV instructions. They are
provided to support more efficient coding. The no-operand version of the instruction divides the contents
of the ST(0) register by the contents of the ST(1) register. The one-operand version
divides the contents of a memory loca-tion (either a real or an integer
value) by the contents of the ST(0) register. The two-operand version,
divides the contents of the ST(i) register by the contents of the ST(0)
register or vice versa. The FDIVRP instructions perform the additional operation of
popping the FPU register stack after storing the result. To pop the register
stack, the processor marks the ST(0) register as empty and increments the
stack pointer (TOP) by 1. The no-operand version of the floating-point divide
instructions always results in the register stack being popped. In some
assemblers, the mnemonic for this instruction is FDIVR rather than FDIVRP.
The FIDIVR instructions convert an integer source operand to extended-real
format before performing the division. If an unmasked divide-by-zero
exception (#Z) is generated, no result is stored; if the exception is masked,
a ∞of
the appropriate sign is stored in the destination operand. |
||||||||||||||||||||||||
|
femms |
Fast emms |
|
3DNOW instruction to fast finish the mmx state |
||||||||||||||||||||||||
|
ffree |
Free Floating-Point Register |
|
Sets the tag in the FPU tag register associated with register
ST(i) to empty (11B). The contents of ST(i) and the FPU stack-top pointer
(TOP) are not affected. |
||||||||||||||||||||||||
|
fildl |
Load Integer 32 |
|
Converts the signed-integer source operand into extended-real
format and pushes the value onto the FPU register stack. The source operand
can be a word, short, or long integer value. It is loaded without rounding
errors. The sign of the source operand is preserved. |
||||||||||||||||||||||||
|
fildq |
Load Integer 64 |
|
|||||||||||||||||||||||||
|
filds |
Load Integer 16 |
|
|||||||||||||||||||||||||
|
fimull |
|
|
|
||||||||||||||||||||||||
|
fimuls |
|
|
|
||||||||||||||||||||||||
|
fincstp |
Increment stack-top pointer |
|
Adds one to the TOP field of the FPU status word (increments the
top-of-stack pointer). If the TOP field contains a 7, it is set to 0. The
effect of this instruction is to rotate the stack by one position. The
contents of the FPU data registers and tag register are not affected. This
operation is not equivalent to popping the stack, because the tag for the
previous top-of-stack register is not marked empty. |
||||||||||||||||||||||||
|
finit |
|
|
|
||||||||||||||||||||||||
|
fistl |
Store integer 32 |
|
The FIST instruction converts the value in the ST(0) register to
a signed integer and stores the result in the destination operand. Values can
be stored in word- or short-integer format. The destination operand specifies
the address where the first byte of the destination value is to be stored. The FISTP instruction performs the same operation as the FIST
instruction and then pops the register stack. To pop the register stack, the
processor marks the ST(0) register as empty and increments the stack pointer
(TOP) by 1. The FISTP instruction can also stores values in long-integer
format. |
||||||||||||||||||||||||
|
fistpl |
Store integer 32 and pop |
|
|||||||||||||||||||||||||
|
fistpq |
Store integer 64 and pop |
|
|||||||||||||||||||||||||
|
fistps |
Store integer 16 and pop |
|
|||||||||||||||||||||||||
|
fists |
Store integer 16 |
|
|||||||||||||||||||||||||
|
fisubl |
|
|
|
||||||||||||||||||||||||
|
fisubrl |
|
|
|
||||||||||||||||||||||||
|
fisubrs |
|
|
|
||||||||||||||||||||||||
|
fisubs |
|
|
|
||||||||||||||||||||||||
|
fld fldl flds |
Load real |
|
Pushes the source operand onto the FPU register stack. If the
source operand is in single- or double-real format, it is automatically
converted to the extended-real format before being pushed on the stack. The FLD instruction can also push the value in a selected FPU
register [ST(i)] onto the stack. Here, pushing register ST(0) duplicates the
stack top. |
||||||||||||||||||||||||
|
fld1 |
Load 1 into FPU stack top |
|
Pushes the value 1.0 into the FPU stack. |
||||||||||||||||||||||||
|
fldcw |
Load x87 FPU Control Word |
|
Loads the 16-bit source operand into the FPU control word. The
source operand is a memory location. This instruction is typically used to
establish or change the FPU’s mode of operation. If one or more exception
flags are set in the FPU status word prior to loading a new FPU control word
and the new control word unmasks one or more of those exceptions, a
floating-point exception will be generated upon execution of the next
floating-point instruction (except for the no-wait floating-point
instructions. To avoid raising exceptions when changing FPU operating modes,
clear any pending exceptions (using the FCLEX or FNCLEX instruction) before
loading the new control word. |
||||||||||||||||||||||||
|
fldenv |
Load x87 FPU Environment |
|
Loads the complete x87 FPU operating environment from memory
into the FPU registers. The source operand specifies the first byte of the
operating-environment data in memory. This data is typically written to the
specified memory location by a FSTENV or FNSTENV instruction. |
||||||||||||||||||||||||
|
fldl2e |
Loads 2**e |
|
Loads the constant 2**e into FPU stack-top |
||||||||||||||||||||||||
|
fldl2t |
|
|
Push log2 base 10 onto the FPU register stack. |
||||||||||||||||||||||||
|
fldlg2 |
|
|
Push log10 base 2 onto the FPU register stack. |
||||||||||||||||||||||||
|
fldln2 |
|
|
Push log e base 2 onto the FPU register stack. |
||||||||||||||||||||||||
|
fldpi |
|
|
Push pi onto the FPU register stack. |
||||||||||||||||||||||||
|
fldt |
Load real 80 |
|
Push extended precision real into FPU stack. |
||||||||||||||||||||||||
|
fldz |
|
|
Push zero into the FPU register stack. |
||||||||||||||||||||||||
|
fmul fmull fmulp fmuls |
Multiply |
|
Multiplies the destination and source operands and stores the
product in the destination location. The destination operand is always an FPU
data register; the source operand can be an FPU data register or a memory
location. Source operands in memory can be in single-real, double-real,
word-integer, or short-integer formats. The no-operand version of the instruction multiplies the
contents of the ST(1) register by the contents of the ST(0) register and
stores the product in the ST(1) register. The one-operand version multiplies
the contents of the ST(0) register by the contents of a memory location
(either a real or an integer value) and stores the product in the ST(0)
register. The two-operand version, multiplies the contents of the ST(0) register by the contents of
the ST(i) register, or vice versa, with the result being stored in the
register specified with the first operand (the destination operand). The FMULP instructions perform the additional operation of
popping the FPU register stack after storing the product. To pop the register
stack, the processor marks the ST(0) register as empty and increments the
stack pointer (TOP) by 1. The no-operand version of the floating-point
multiply instructions always results in the register stack being popped. In
some assem-blers, the mnemonic for this instruction is FMUL rather than
FMULP. The FIMUL instructions convert an integer source operand to
extended-real format before performing the multiplication. The sign of the result is always the exclusive-OR of the source
signs, even if one or more of the values being multiplied is 0 or ∞.
When the source operand is an integer 0, it is treated as a +0. |
||||||||||||||||||||||||
|
fnclex |
|
|
|
||||||||||||||||||||||||
|
fninit |
|
|
|
||||||||||||||||||||||||
|
fnop |
No operation |
|
|
||||||||||||||||||||||||
|
fnstenv |
|
|
|
||||||||||||||||||||||||
|
fnstsw |
|
|
|
||||||||||||||||||||||||
|
fpatan |
|
|
Computes the arctangent of the source operand in register ST(1)
divided by the source operand in register ST(0), stores the result in ST(1),
and pops the FPU register stack. The result in register ST(0) has the same
sign as the source operand ST(1) and a magnitude less than +π . The FPATAN instruction returns the angle between the X axis and
the line from the origin to the point (X,Y), where Y (the ordinate) is ST(1)
and X (the abscissa) is ST(0). The angle depends on the sign of X and Y
independently, not just on the sign of the ratio Y/X. This is because a point
(X,Y) is in the second quadrant, resulting in an angle between π /2 and
π , while a point (X,−Y) is in the fourth quadrant, resulting in
an angle between 0 and −π /2. A point (X,−Y) is in the third
quadrant, giving an angle between −π /2 and −π |
||||||||||||||||||||||||
|
fprem |
Partial Remainder |
|
Computes the remainder obtained from dividing the value in the
ST(0) register (the dividend) by the value in the ST(1) register (the divisor
or modulus), and stores the result in ST(0). The remainder represents the
following value: Remainder ←ST(0)
−(Q ∗ST(1)) Here, Q is an integer value that is obtained by truncating the
real-number quotient of [ST(0) / ST(1)] toward zero. The sign of the
remainder is the same as the sign of the dividend. The magnitude of the
remainder is less than that of the modulus, unless a partial remainder was
computed (as described below). This instruction produces an exact result; the precision
(inexact) exception does not occur and the rounding control has no effect. |
||||||||||||||||||||||||
|
fprem1 |
Partial remainder |
|
Computes the IEEE remainder obtained from dividing the value in
the ST(0) register (the dividend) by the value in the ST(1) register (the
divisor or modulus), and stores the result in ST(0). The remainder represents the following value: Remainder ←ST(0)
−(Q ∗ST(1)) Here, Q is an integer value that is obtained by rounding the
real-number quotient of [ST(0) / ST(1)] toward the nearest integer value. The
magnitude of the remainder is less than half the magnitude of the modulus,
unless a partial remainder was computed (as described below). This instruction produces an exact result; the precision
(inexact) exception does not occur and the rounding control has no effect. |
||||||||||||||||||||||||
|
fptan |
Partial tangent |
|
Computes the tangent of the source operand in register ST(0),
stores the result in ST(0), and pushes a 1.0 onto the FPU register stack. The
source operand must be given in radians and must be less than ±2 63 . |
||||||||||||||||||||||||
|
frndint |
Round to Integer |
|
Rounds the source value in the ST(0) register to the nearest
integral value, depending on the current rounding mode (setting of the RC field
of the FPU control word), and stores the result in ST(0). If the source value is ∞,
the value is not changed. If the source value is not an integral value, the
floating-point inexact-result exception (#P) is generated. |
||||||||||||||||||||||||
|
frstor |
Restore x87 FPU State |
|
Loads the FPU state (operating environment and register stack)
from the memory area specified with the source operand. This state data is
typically written to the specified memory location by a previous FSAVE/FNSAVE
instruction. The FPU operating environment consists of the FPU control word,
status word, tag word, instruction pointer, data pointer, and last opcode.
Figures 7-13 through 7-16 in the IA-32 Intel Architecture Software
Developer’s Manual, Volume 1, show the layout in memory of the stored
environment, depending on the operating mode of the processor (protected or
real) and the current operand-size attribute (16-bit or 32-bit). In
virtual-8086 mode, the real mode layouts are used. The contents of the FPU
register stack are stored in the 80 bytes immediately follow the operating
environment image. The FRSTOR instruction should be executed in the same operating
mode as the corresponding FSAVE/FNSAVE instruction. If one or more unmasked exception bits are set in the new FPU
status word, a floating-point exception will be generated. To avoid raising
exceptions when loading a new operating environment, clear all the exception
flags in the FPU status word that is being loaded. |
||||||||||||||||||||||||
|
fsave fnsave |
Store x87 FPU State |
|
Stores the current FPU state (operating environment and register
stack) at the specified destination in memory, and then re-initializes the
FPU. The FSAVE instruction checks for and handles pending unmasked
floating-point exceptions before storing the FPU state; the FNSAVE
instruction does not. The FPU operating environment consists of the FPU control word,
status word, tag word, instruction pointer, data pointer, and last opcode.
The contents of the FPU register stack are stored in the 80 bytes immediately
follow the operating environment image. The saved image reflects the state of the FPU after all
floating-point instructions preceding the FSAVE/FNSAVE instruction in the
instruction stream have been executed. After the FPU state has been saved, the FPU is reset to the same
default values it is set to with the FINIT/FNINIT instructions (see
“FINIT/FNINIT—Initialize Floating-Point Unit” in this table). The FSAVE/FNSAVE instructions are typically used when the
operating system needs to perform a context switch, an exception handler
needs to use the FPU, or an application program needs to pass a “clean” FPU
to a procedure. |
||||||||||||||||||||||||
|
fscale |
Scale |
|
Multiplies the destination operand by 2 to the power of the
source operand and stores the result in the destination operand. The
destination operand is a real value that is located in register ST(0). The
source operand is the nearest integer value that is smaller than the value in
the ST(1) register (that is, the value in register ST(1) is truncated toward
0 to its nearest integer value to form the source operand). This instruction
provides rapid multiplication or division by integral powers of 2 because it
is implemented by simply adding an integer value (the source operand) to the
exponent of the value in register ST(0). |
||||||||||||||||||||||||
|
fsin |
Sine |
|
Computes the sine of the source operand in register ST(0) and
stores the result in ST(0). The source operand must be given in radians and
must be within the range −2 63 to +2 63 . |
||||||||||||||||||||||||
|
fsincos |
Sine and Cosine |
|
Computes both the sine and the cosine of the source operand in
register ST(0), stores the sine in ST(0), and pushes the cosine onto the top
of the FPU register stack. (This instruction is faster than executing the
FSIN and FCOS instructions in succession.) The source operand must be given
in radians and must be within the range −2** 63 to +2** 63 |
||||||||||||||||||||||||
|
fsqrt |
Square root |
|
Computes the square root of the source value in the ST(0)
register and stores the result in ST(0). |
||||||||||||||||||||||||
|
fst fstl fstp fstpl fstps fstpt fsts |
Store real Store 64 bit real Store and pop Store 64 and pop Store 32 bit real |
|
The FST instruction copies the value in the ST(0) register to
the destination operand, which can be a memory location or another register
in the FPU register stack. When storing the value in memory, the value is
converted to single- or double-real format. The FSTP instruction performs the
same operation as the FST instruction and then pops the register stack. To pop
the register stack, the processor marks the ST(0) register as empty and
increments the stack pointer (TOP) by 1. The FSTP instruction can also store
values in memory in extended-real format. If the destination operand is a memory location, the operand specifies
the address where the first byte of the destination value is to be stored. If
the destination operand is a register, the operand specifies a register in
the register stack relative to the top of the stack. If the destination size
is single- or double-real, the significand of the value being stored is
rounded to the width of the destination (according to rounding mode specified
by the RC field of the FPU control word), and the exponent is converted to
the width and bias of the destination format. If the value being stored is
too large for the destination format, a numeric overflow exception (#O) is
generated and, if the exception is unmasked, no value is stored in the
destination operand. If the value being stored is a denormal value, the
denormal exception (#D) is not generated. This condition is simply signaled
as a numeric underflow exception (#U) condition. If the value being stored is ±0, ±, or a NaN, the
least-significant bits of the significand and the exponent are truncated to
fit the destination format. This operation preserves the value’s identity as
a 0, ∞,or
NaN. If the destination operand is a non-empty register, the
invalid-operation exception is not generated. |
||||||||||||||||||||||||
|
fstcw fnstcw |
Store x87 control word |
|
Stores the current value of the FPU control word at the
specified destination in memory. The FSTCW instruction checks for and handles
pending unmasked floating-point exceptions before storing the control word;
the FNSTCW instruction does not. |
||||||||||||||||||||||||
|
fstenv fnstenv |
Store x87 FPU Environment |
|
Saves the current FPU operating environment at the memory
location specified with the destination operand, and then masks all
floating-point exceptions. The FPU operating environment consists of the FPU
control word, status word, tag word, instruction pointer, data pointer, and
last opcode. The FSTENV instruction checks for and handles any pending
unmasked floating-point exceptions before storing the FPU environment; the
FNSTENV instruction does not. The saved image reflects the state of the FPU
after all floating-point instructions preceding the FSTENV/FNSTENV
instruction in the instruction stream have been executed. These instructions
are often used by exception handlers because they provide access to the FPU
instruction and data pointers. The environment is typically saved in the
stack. Masking all exceptions after saving the environment prevents
floating-point exceptions from interrupting the exception handler. |
||||||||||||||||||||||||
|
fsts |
|
|
|
||||||||||||||||||||||||
|
fstsw |
|
|
|
||||||||||||||||||||||||
|
fsub fsubl fsubs fsubp fisub fisubp |
Substract |
|
Subtracts the source operand from the destination operand and
stores the difference in the desti-nation location. The destination operand
is always an FPU data register; the source operand can be a register or a
memory location. Source operands in memory can be in single-real,
double-real, word-integer, or short-integer formats. The no-operand version
of the instruction subtracts the contents of the ST(0) register from the
ST(1) register and stores the result in ST(1). The one-operand version
subtracts the contents of a memory location (either a real or an integer
value) from the contents of the ST(0) register and stores the result in
ST(0). The two-operand version, subtracts the contents of the ST(0) register
from the ST(i) register or vice versa. The FSUBP instructions perform the additional operation of
popping the FPU register stack following the subtraction. To pop the register
stack, the processor marks the ST(0) register as empty and increments the
stack pointer (TOP) by 1. The no-operand version of the floating-point
subtract instructions always results in the register stack being popped. In
some assemblers, the mnemonic for this instruction is FSUB rather than FSUBP. The FISUB instructions convert an integer source operand to
extended-real format before performing the subtraction. When the difference between two operands of like sign is 0, the
result is +0, except for the round toward −∞mode,
in which case the result is −0. This instruction also guarantees that
+0 −(0) ←+0,
and that −0 −(+0) ←−0.
When the source operand is an integer 0, it is treated as a +0. When one operand is ∞,
the result is ∞of
the expected sign. If both operands are ∞of
the same sign, an invalid-operation exception is generated. |
||||||||||||||||||||||||
|
fsubrl |
|
|
|
||||||||||||||||||||||||
|
fsubrp |
|
|
|
||||||||||||||||||||||||
|
fsubrs |
|
|
|
||||||||||||||||||||||||
|
ftst |
Test |
|
Compares the value in the ST(0) register with 0.0 and sets the
condition code flags C0, C2, and C3 in the FPU status word according to the
results.
|
||||||||||||||||||||||||
|
fucom fucomi fucomip fucomp fucompp |
Compare Real |
|
The FCOM instructions perform the same operation as the FUCOM
instructions. The only difference is how they handle QNaN operands. The FCOM
instructions raise an invalid arithmetic operand exception (#IA) when either
or both of the operands is a NaN value or is in an unsupported format. The
FUCOM instructions perform the same operation as the FCOM instructions,
except that they do not generate an invalid-arithmetic-operand exception for
QNaNs. |
||||||||||||||||||||||||
|
fxam |
Examine |
|
Examines the contents of the ST(0) register and sets the
condition code flags C0, C2, and C3 in the FPU status word to indicate the class
of value or number in the register. |
||||||||||||||||||||||||
|
fxch |
Exchange Register Contents |
|
Exchanges the contents of registers ST(0) and ST(i). If no
source operand is specified, the contents of ST(0) and ST(1) are exchanged. This instruction provides a simple means of moving values in the
FPU register stack to the top of the stack [ST(0)], so that they can be
operated on by those floating-point instructions that can only operate on
values in ST(0). For example, the following instruction sequence takes the
square root of the third register from the top of the register stack: FXCH ST(3); FSQRT; FXCH ST(3); |
||||||||||||||||||||||||
|
fxtract |
Extract Exponent and Significand |
|
Separates the source value in the ST(0) register into its
exponent and significand, stores the exponent in ST(0), and pushes the significand
onto the register stack. Following this operation, the new top-of-stack
register ST(0) contains the value of the original significand expressed as a
real number. The sign and significand of this value are the same as those
found in the source operand, and the exponent is 3FFFH (biased value for a
true exponent of zero). The ST(1) register contains the value of the original
operand’s true (unbiased) exponent expressed as a real number. (The operation
performed by this instruction is a superset of the IEEE-recommended logb(x)
function.) This instruction and the F2XM1 instruction are useful for
performing power and range scaling operations. The FXTRACT instruction is
also useful for converting numbers in extended-real format to decimal
representations (e.g., for printing or displaying). If the floating-point
zero-divide exception (#Z) is masked and the source operand is zero, an
exponent value of –is stored in register ST(1) and 0 with the sign of the
source operand is stored in register ST(0). |
||||||||||||||||||||||||
|
fyl2x |
Compute y * log2x |
|
Computes (ST(1) * log2 (ST(0))), stores the result in resister
ST(1), and pops the FPU register stack. The source operand in ST(0) must be a
non-zero positive number. |
||||||||||||||||||||||||
|
fyl2xp1 |
Compute y * log2(x
+1) |
|
Computes the log epsilon (ST(1) ∗log2 (ST(0) + 1.0)),
stores the result in register ST(1), and pops the FPU register stack. The
source operand in ST(0) must be in the range: -(1- sqrt(2)/2) to (1 – sqrt(2)/2) The source operand in ST(1) can range from −∞to
+∞.
If the ST(0) operand is outside of its acceptable range, the result is
undefined and software should not rely on an exception being generated. Under
some circumstances exceptions may be generated when ST(0) is out of range,
but this behavior is implementation specific and not guaranteed. |
||||||||||||||||||||||||
|
hlt |
Halt |
|
Stops instruction execution and places the processor in a HALT
state. An enabled interrupt, NMI, or a reset will resume execution. If an
interrupt (including NMI) is used to resume execution after a HLT instruction,
the saved instruction pointer (CS:EIP) points to the instruction following
the HLT instruction. The HLT instruction is a privileged instruction. When
the processor is running in protected or virtual-8086 mode, the privilege
level of a program or procedure must be 0 to execute the HLT instruction. |
||||||||||||||||||||||||
|
idiv |
Signed divide |
|
Divides (signed) the value in the AL, AX, or EAX register by the
source operand and stores the result in the AX, DX:AX, or EDX:EAX registers.
The source operand can be a general-purpose register or a memory location.
The action of this instruction depends on the operand size, as shown in the
following table:
|
||||||||||||||||||||||||
|
imul |
Signed multiply |
|
Performs a signed multiplication of two operands. This
instruction has three forms, depending on the number of operands. • One-operand form. This form is identical to that used by the
MUL instruction. Here, the source operand (in a general-purpose register or
memory location) is multiplied by the value in the AL, AX, or EAX register
(depending on the operand size) and the product is stored in the AX, DX:AX,
or EDX:EAX registers, respectively. • Two-operand form. With this form the destination operand (the
first operand) is multiplied by the source operand (second operand). The destination
operand is a general-purpose register and the source operand is an immediate
value, a general-purpose register, or a memory location. The product is then
stored in the destination operand location. • Three-operand form. This form requires a destination operand
(the first operand) and two source operands (the second and the third
operands). Here, the first source operand (which can be a general-purpose
register or a memory location) is multiplied by the second source operand (an
immediate value). The product is then stored in the destination operand (a
general-purpose register). When an immediate value is used as an operand, it
is sign-extended to the length of the destination operand format. The CF and OF flags are set when significant bits are carried
into the upper half of the result. The CF and OF flags are cleared when the result fits exactly in
the lower half of the result. The three forms of the IMUL instruction are similar in that the
length of the product is calculated to twice the length of the operands. With
the one-operand form, the product is stored exactly in the destination. With
the two- and three- operand forms, however, result is truncated to the length
of the destination before it is stored in the destination register. Because
of this truncation, the CF or OF flag should be tested to ensure that no
significant bits are lost. The two- and three-operand forms may also be used with unsigned
operands because the lower half of the product is the same regardless if the
operands are signed or unsigned. The CF and OF flags, however, cannot be used
to determine if the upper half of the result is non-zero. |
||||||||||||||||||||||||
|
in |
Input from port |
|
Copies the value from the I/O port specified with the first
operand (source operand) to the destination operand (second operand). The
source operand can be a byte-immediate or the DX register; the destination
operand can be register AL, AX, or EAX, depending on the size of the port
being accessed (8, 16, or 32 bits, respectively). Using the DX register as a
source operand allows I/O port addresses from 0 to 65,535 to be accessed;
using a byte immediate allows I/O port addresses 0 to 255 to be accessed. When accessing an 8-bit I/O port, the opcode determines the port
size; when accessing a 16- and 32-bit I/O port, the operand-size attribute
determines the port size. At the machine code level, I/O instructions are shorter when
accessing 8-bit I/O ports. Here, the upper eight bits of the port address
will be 0. |
||||||||||||||||||||||||
|
inc |
Increment by 1 |
|
Adds 1 to the destination operand, while preserving the state of
the CF flag. The destination operand can be a register or a memory location.
This instruction allows a loop counter to be updated without disturbing the
CF flag. (Use a ADD instruction with an immediate operand of 1 to perform an
increment operation that does updates the CF flag.) |
||||||||||||||||||||||||
|
ins |
Input from Port to String |
|
Copies the data from the I/O port specified with the source
operand (second operand) to the destination operand (first operand). The
source operand is an I/O port address (from 0 to 65,535) that is read from
the DX register. The destination operand is a memory location, the address of
which is read from either the ES:EDI or the ES:DI registers (depending on the
address-size attribute of the instruction, 32 or 16, respectively). (The ES
segment cannot be overridden with a segment override prefix.) The size of the
I/O port being accessed (that is, the size of the source and destination
operands) is determined by the opcode for an 8-bit I/O port or by the
operand-size attribute of the instruction for a 16- or 32-bit I/O port. |
||||||||||||||||||||||||
|
int int01 int3 |
Call to Interrupt Procedure |
|
The INT n instruction generates a call to the interrupt or
exception handler specified with the destination operand. The destination
operand specifies an interrupt vector number from 0 to 255, encoded as an
8-bit unsigned intermediate value. Each interrupt vector number provides an index to a gate descriptor
in the IDT. The first 32 interrupt vector numbers are reserved by Intel for system use. Some of
these interrupts are used for internally generated exceptions. The INT n instruction is the general mnemonic for executing a
software-generated call to an interrupt handler. The INTO instruction is a
special mnemonic for calling overflow exception (#OF), interrupt vector
number 4. The overflow interrupt checks the OF flag in the EFLAGS register
and calls the overflow interrupt handler if the OF flag is set to 1. The INT 3 instruction generates a special one byte opcode (CC)
that is intended for calling the debug exception handler. (This one byte form
is valuable because it can be used to replace the first byte of any
instruction with a breakpoint, including other one byte instructions, without
overwriting other code). To further support its function as a debug
breakpoint, the interrupt generated with the CC opcode also differs from the
regular software interrupts as follows: • Interrupt redirection does not happen when in VME mode; the
interrupt is handled by a protected-mode handler. • The virtual-8086 mode IOPL checks do not occur. The interrupt
is taken without faulting at any IOPL level. Note that the “normal” 2-byte opcode for INT 3 (CD03) does not
have these special features. Intel and Microsoft assemblers will not generate
the CD03 opcode from any mnemonic, but this opcode can be created by direct
numeric code definition or by self-modifying code. The action of the INT n instruction (including the INTO and INT
3 instructions) is similar to that of a far call made with the CALL
instruction. The primary difference is that with the INT n instruction, the
EFLAGS register is pushed onto the stack before the return address. (The
return address is a far address consisting of the current values of the CS
and EIP registers.) Returns from interrupt procedures are handled with the
IRET instruction, which pops the EFLAGS information and return address from
the stack. |
||||||||||||||||||||||||
|
into |
interrupt if overflow |
|
|
||||||||||||||||||||||||
|
invd |
Invalidate Internal Caches |
|
Invalidates
(flushes) the processor’s internal caches and issues a special-function bus
cycle that directs external caches to also flush themselves. Data held in
internal caches is not written back to main memory. After
executing this instruction, the processor does not wait for the external
caches to complete their flushing operation before proceeding with instruction
execution. It is the responsibility of hardware to respond to the cache flush
signal. The INVD instruction is a privileged instruction. When the processor
is running in protected mode, the CPL of a program or procedure must be 0 to
execute this instruction. Use this
instruction with care. Data cached internally and not written back to main
memory will be lost. Unless there is a specific requirement or benefit to
flushing caches without writing back modified cache lines (for example,
testing or fault recovery where cache coherency with main memory is not a
concern), software should use the WBINVD instruction. |
||||||||||||||||||||||||
|
iret |
Interrupt return |
|
Returns program control from an exception or interrupt handler
to a program or procedure that was interrupted by an exception, an external
interrupt, or a software-generated interrupt. These instructions are also
used to perform a return from a nested task. (A nested task is created when a
CALL instruction is used to initiate a task switch or when an interrupt or
exception causes a task switch to an interrupt or exception handler.) |
||||||||||||||||||||||||
|
ja |
Jump short if above (CF=0 and ZF=0) |
|
Jump according to flags. |
||||||||||||||||||||||||
|
jae |
Jump short if above or equal (CF=0) |
|
|||||||||||||||||||||||||
|
jb |
Jump short if below (CF=1) |
|
|||||||||||||||||||||||||
|
jbe |
Jump short if below or equal (CF=1 or ZF=1) |
|
|||||||||||||||||||||||||
|
jc |
Jump short if carry (CF=1) |
|
|||||||||||||||||||||||||
|
jcxz |
Jump short if CX register is 0 |
|
|||||||||||||||||||||||||
|
je |
Jump short if equal (ZF=1) |
|
|||||||||||||||||||||||||
|
jecxz |
Jump short if ECX register is 0 |
|
|||||||||||||||||||||||||
|
jg |
Jump short if greater (ZF=0 and SF=OF) |
|
|||||||||||||||||||||||||
|
jge |
Jump short if greater or equal (SF=OF) |
|
|||||||||||||||||||||||||
|
jl |
Jump short if less (SF<>OF) |
|
|||||||||||||||||||||||||
|
jle |
Jump short if less or equal (ZF=1 or SF<>OF) |
|
|||||||||||||||||||||||||
|
jna |
Jump short if not above (CF=1 or ZF=1) |
|
|||||||||||||||||||||||||
|
jnae |
Jump short if not above or equal (CF=1) |
|
|||||||||||||||||||||||||
|
jnb |
Jump short if not below (CF=0) |
|
|||||||||||||||||||||||||
|
jnbe |
Jump short if not below or equal (CF=0 and ZF=0) |
|
|||||||||||||||||||||||||
|
jnc |
Jump short if not carry (CF=0) |
|
|||||||||||||||||||||||||
|
jne |
Jump short if not equal (ZF=0) |
|
|||||||||||||||||||||||||
|
jng |
Jump short if not greater (ZF=1 or SF<>OF) |
|
|||||||||||||||||||||||||
|
jnge |
Jump short if not greater or equal (SF<>OF) |
|
|||||||||||||||||||||||||
|
jnl |
Jump short if not less (SF=OF) |
|
|||||||||||||||||||||||||
|
jnle |
Jump short if not less or equal (ZF=0 and SF=OF) |
|
|||||||||||||||||||||||||
|
jno |
Jump short if not overflow (OF=0) |
|
|||||||||||||||||||||||||
|
jnp |
Jump short if not parity (PF=0) |
|
|||||||||||||||||||||||||
|
jns |
Jump
short if not sign (SF=0) |
|
|||||||||||||||||||||||||
|
jnz |
Jump
short if not zero (ZF=0) |
|
|||||||||||||||||||||||||
|
jo |
Jump
short if overflow (OF=1) |
|
|||||||||||||||||||||||||
|
jp |
Jump
short if parity (PF=1) |
|
|||||||||||||||||||||||||
|
jpe |
Jump
short if parity even (PF=1) |
|
|||||||||||||||||||||||||
|
jpo |
Jump
short if parity odd (PF=0) |
|
|||||||||||||||||||||||||
|
js |
Jump
short if sign (SF=1) |
|
|||||||||||||||||||||||||
|
jz |
Jump
short if zero (ZF is 1) |
|
|||||||||||||||||||||||||
|
jmp |
|
|
Transfers
program control to a different point in the instruction stream without
recording return information. The destination (target) operand specifies the
address of the instruction being jumped to. This operand can be an immediate
value, a general-purpose register, or a memory location. |
||||||||||||||||||||||||
|
lahf |
Load:
AH into EFLAGS(SF:ZF:0:AF:0:PF:1:CF) |
|
Moves the
low byte of the EFLAGS register (which includes status flags SF, ZF, AF, PF,
and CF) to the AH register. Reserved bits 1, 3, and 5 of the EFLAGS register
are set in the AH register |
||||||||||||||||||||||||
|
lar |
r16
.r/m16 masked by FF00H r32
.r/m32 masked by 00FxFF00H |
|
Loads the access
rights from the segment descriptor specified by the first operand (source
operand) into the second operand (destination operand) and sets the ZF flag
in the EFLAGS register. The source operand (which can be a register or a
memory location) contains the segment selector for the segment descriptor
being accessed. The destination operand is a general-purpose
register. |
||||||||||||||||||||||||
|
lcall |
Call
far, absolute, address given in operand or in a register |
|
See call instruction. |
||||||||||||||||||||||||
|
lds |
Loads DS from memory |
|
Loads a far pointer
(segment selector and offset) from the first operand (source operand) into a
segment register from the second operand (destination operand). The source
operand specifies a 48-bit or a 32-bit pointer in memory depending on the
current setting of the operand-size attribute
(32 bits or 16 bits, respectively). |
||||||||||||||||||||||||
|
ldmxscr |
Load MXCSR Register SSE/SSE2
Instruction |
|
Loads the source
operand into the MXCSR control/status register. The source operand is a
32-bit memory location. The LDMXCSR
instruction is typically used in conjunction with the STMXCSR instruction,
which stores the contents of the MXCSR register in memory. The default MXCSR
value at reset is 1F80H. If a LDMXCSR instruction clears a SIMD
floating-point exception mask bit and sets the corresponding exception flag
bit, a SIMD floating-point exception will not be immediately generated. The
exception will be generated only upon the execution of the next SSE or SSE2
instruction that causes that particular SIMD floating-point exception to be
reported. |
||||||||||||||||||||||||
|
lea |
Load Effective Address |
|
Computes the effective
address of the first operand (the source operand) and stores it in the second
operand (destination operand). The source operand is a memory address (offset
part) specified with one of the processors addressing modes; the destination
operand is a general-purpose register. The address-size and operand-size
attributes affect the action performed by this instruction, as shown in the
following table. The operand-size attribute of the instruction is determined
by the chosen register; the address-size attribute is determined by the
attribute of the code segment.
|
||||||||||||||||||||||||
|
leave |
High Level Procedure Exit |
|
Releases the stack
frame set up by an earlier ENTER instruction. The LEAVE instruction copies
the frame pointer (in the EBP register) into the stack pointer register
(ESP), which releases the stack space allocated to the stack frame. The old
frame pointer (the frame pointer for the calling procedure
that was saved by the ENTER instruction) is then popped from the stack into
the EBP register, restoring the calling procedure’s stack frame. A RET
instruction is commonly executed following a LEAVE instruction to return
program control to the calling procedure. |
||||||||||||||||||||||||
|
les |
Load Far Pointer |
|
Same as LDS instruction but here is the ES register loaded. |
||||||||||||||||||||||||
|
lfence |
Load Fence |
|
Performs a serializing operation on all load-from-memory
instructions that were issued prior the LFENCE instruction. This serializing
operation guarantees that every load instruction that precedes in program
order the LFENCE instruction is globally visible before any load instruction
that follows the LFENCE instruction is globally visible. The LFENCE
instruction is ordered with respect to load instructions, other LFENCE
instructions, any MFENCE instructions, and any serializing instructions (such
as the CPUID instruction). It is not ordered with respect to store
instructions or the SFENCE instruction. Weakly ordered memory types can be used to achieve higher
processor performance through such techniques as out-of-order issue and
speculative reads. The degree to which a consumer of data recognizes or knows
that the data is weakly ordered varies among applications and may be unknown
to the producer of this data. The LFENCE instruction provides a
performance-efficient way of insuring load ordering between routines that
produce weakly ordered results and routines that consume that data. It should be noted that processors are free to speculatively
fetch and cache data from system memory regions that are assigned a
memory-type that permits speculative reads (that is, the WB, WC, and WT
memory types). The PREFETCHh instruction is considered a hint to this
speculative behavior. Because this speculative fetching can occur at any time
and is not tied to instruction execution, the LFENCE instruction is not
ordered with respect to PREFETCHh instructions or any other speculative
fetching mechanism (that is, data could be speculative loaded into the cache
just before, during, or after the execution of an LFENCE instruction). |
||||||||||||||||||||||||
|
lfs |
Load Far Pointer |
|
Same as LDS instruction but here is the FS register loaded. |
||||||||||||||||||||||||
|
lgdt |
Load Global/Interrupt Descriptor Table Register |
|
Loads the values in
the source operand into the global descriptor table register (GDTR) or the
interrupt descriptor table register (IDTR). The source operand specifies a
6-byte memory location that contains the base address (a linear address) and
the limit (size of table in bytes) of the global descriptor table (GDT) or
the interrupt descriptor table (IDT). If operand-size attribute is 32 bits, a
16-bit limit (lower 2 bytes of the 6-byte data operand) and a 32-bit base
address (upper 4 bytes of the data operand) are loaded into the register. If
the operand-size attribute is 16 bits, a 16-bit limit (lower 2 bytes) and a
24-bit base address (third, fourth, and fifth byte) are loaded. Here, the
high-order byte of the operand is not used and the high-order byte of the
base address in the GDTR or IDTR is filled with zeros. The LGDT
and LIDT instructions are used only in operating-system software; they are
not used in application programs. They are the only instructions that
directly load a linear address (that is, not a segment-relative address) and
a limit in protected mode. They are commonly executed in real-address mode to
allow processor initialization prior to switching to protected mode. |
||||||||||||||||||||||||
|
lgs |
Load Far Pointer |
|
Same as LDS instruction but here is the GS register loaded. |
||||||||||||||||||||||||
|
lidt |
Load Far Pointer |
|
See description for lgdt instruction. |
||||||||||||||||||||||||
|
ljmp |
Long jump |
|
See description of the JMP instruction. |
||||||||||||||||||||||||
|
lldt |
|
|
|
||||||||||||||||||||||||
|
lmsw |
Load Machine Status Word |
|
Loads the source
operand into the machine status word, bits 0 through 15 of register CR0. The
source operand can be a 16-bit general-purpose register or a memory location.
Only the low-order 4 bits of the source operand (which contains the PE, MP,
EM, and TS flags) are loaded into CR0. The PG, CD,
NW, AM, WP, NE, and ET flags of CR0 are not affected. The operand-size
attribute has no effect on this instruction. If the PE flag of the
source operand (bit 0) is set to 1, the instruction causes the processor to
switch to protected mode. While in protected mode, the LMSW instruction
cannot be used clear the PE flag and force a switch back to real-address
mode. The LMSW instruction is provided for use in operating-system software;
it should not be used in application programs. In protected or virtual-8086
mode, it can only be executed at CPL 0. This instruction is
provided for compatibility with the Intel 286™ processor; programs and
procedures intended to run on the Pentium 4, P6 family, Pentium, Intel486,
and Intel386 proces-sors should use the MOV (control registers) instruction
to load the whole CR0 register. The MOV CR0
instruction can be used to set and clear the PE flag in CR0, allowing a
procedure or program to switch between protected and real-address modes. This
instruction is a serializing instruction. |
||||||||||||||||||||||||
|
lods |
Load String |
|
Loads a byte, word, or
doubleword from the source operand into the AL, AX, or EAX register,
respectively. The source operand is a memory location, the address of which
is read from the DS:EDI or the DS:SI registers (depending on the address-size
attribute of the instruction, 32 or 16, respectively). The
DS segment may be overridden with a segment override prefix. At the
assembly-code level, two forms of this instruction are allowed: the
“explicit-operands” form and the “no-operands” form. The explicit-operands
form (specified with the LODS mnemonic) allows the source operand to be
specified explicitly. Here, the source operand should be a symbol that
indicates the size and location of the source value. The destination operand
is then automatically selected to match the size of the source operand (the
AL register for byte operands, AX for word operands, and EAX for doubleword
operands). This explicit-operands form is provided to allow documentation;
however, note that the documentation provided by this form can be misleading.
That is, the source operand symbol must specify the correct type (size) of the operand
(byte, word, or doubleword), but it does not have to specify the correct location. The location is always
specified by the DS:(E)SI registers, which must be loaded correctly before
the load string instruction is executed. The no-operands form
provides “short forms” of the byte, word, and doubleword versions of the LODS
instructions. Here also DS:(E)SI is assumed to be the source operand and the
AL, AX, or EAX register is assumed to be the destination operand. The size of
the source and destination operands is selected with the mnemonic: LODSB
(byte loaded into register AL), LODSW (word loaded into AX), or LODSD
(doubleword loaded into EAX). After the byte, word, or doubleword is
transferred from the memory location into the AL, AX, or EAX register, the
(E)SI register is incremented or decremented automatically according to the
setting of the DF flag in the EFLAGS register. (If the DF flag is 0, the
(E)SI register is incre-mented; if the DF flag is 1, the ESI register is
decremented.) The (E)SI register is incremented or decremented by 1 for byte
operations, by 2 for word operations, or by 4 for doubleword oper-ations. The
LODS, LODSB, LODSW, and LODSD instructions can be preceded by the REP prefix
for block loads
of ECX bytes, words, or doublewords. More often, however, these instructions
are used within a LOOP construct because further processing of the data moved
into the register is usually necessary before the next transfer can be made. |
||||||||||||||||||||||||
|
loop |
Loop According to ECX Counter |
|
Performs a loop
operation using the ECX or CX register as a counter. Each time the LOOP
instruction is executed, the count register is decremented, then checked for
0. If the count is 0, the loop is terminated and program execution continues
with the instruction following the LOOP instruction. If the count is not
zero, a near jump is performed to the destination (target) operand, which is
presumably the instruction at the beginning of the loop. If the address-size
attribute is 32 bits, the ECX register is used as the count register;
otherwise the CX register is used. The target instruction is specified with a
relative offset (a signed offset relative to the current value of the
instruction pointer in the EIP register). This offset is generally specified
as a label in assembly code, but at the machine code level, it is encoded as
a signed, 8-bit immediate value, which is added to the instruction pointer.
Offsets of –128 to +127 are allowed with this instruction.
|
||||||||||||||||||||||||
|
loope |
LOOP with condition |
|
Some forms
of the loop instruction (LOOPcc) also accept the ZF flag as a
condition for terminating the loop before the count reaches zero. With these
forms of the instruction, a condition code (cc)
is associated with each instruction to indicate the condition being tested
for. Here, the LOOPcc
instruction itself
does not affect the state of the ZF flag; the ZF flag is changed by other
instructions in the loop. |
||||||||||||||||||||||||
|
loopne |
|
||||||||||||||||||||||||||
|
loopnz |
|
||||||||||||||||||||||||||
|
loopz |
|
||||||||||||||||||||||||||
|
lret |
Return |
|
See RET instruction. This is used for an intrasegment return. |
||||||||||||||||||||||||
|
lsl |
|
|
Loads the unscrambled
segment limit from the segment descriptor specified with the first operand
(source operand) into the second operand (destination operand) and sets the
ZF flag in the EFLAGS register. The source operand (which can be a register
or a memory location) contains the segment selector
for the segment descriptor being accessed. The destination operand is a
general-purpose register. The processor performs
access checks as part of the loading process. Once loaded in the destination
register, software can compare the segment limit with the offset of a
pointer. The segment limit is a
20-bit value contained in bytes 0 and 1 and in the first 4 bits of byte 6 of
the segment descriptor. If the descriptor has a byte granular segment limit
(the granularity flag is set to 0), the destination operand is loaded with a
byte granular value (byte limit). If the descriptor has a page
granular segment limit (the granularity flag is set to 1), the LSL
instruction will translate the page granular limit (page limit) into a byte
limit before loading it into the destination operand. The translation is
performed by shifting the 20-bit “raw” limit left 12 bits and filling the
low-order 12 bits with 1s. When the operand size is
32 bits, the 32-bit byte limit is stored in the destination operand. When the
operand size is 16 bits, a valid 32-bit limit is computed; however, the upper
16 bits are truncated and only the low-order 16 bits are loaded into the
destination operand. This instruction
performs the following checks before it loads the segment limit into the
destination register: • Checks that the
segment selector is not null. • Checks that the
segment selector points to a descriptor that is within the limits of the GDT
or LDT being accessed • Checks that the
descriptor type is valid for this instruction. All code and data segment
descriptors are valid for (can be accessed with) the LSL instruction. •
If the segment is not a
conforming code segment, the instruction checks that the specified segment
descriptor is visible at the CPL (that is, if the CPL and the RPL of the
segment selector are less than or equal to the DPL of the segment selector).
If the segment descriptor cannot be accessed or is an invalid type for the
instruction, the ZF flag is cleared and no value is loaded in the destination
operand. |
||||||||||||||||||||||||
|
lss |
Load far pointer |
|
See LDS instruction. Here the SS register is loaded. |
||||||||||||||||||||||||
|
ltr |
|
|
|
||||||||||||||||||||||||
|
maskmovdqu |
Store Selected Bytes of Double Quadword. SSE/SSE2
Instruction. |
|
Stores selected bytes
from the source operand (second operand) into an 128-bit memory location. The mask operand
(first operand) selects which bytes from the source operand are written to
memory. The source and mask operands are XMM registers. The location of the
first byte of the memory location is specified by DI/EDI and DS registers.
The memory location does not need to be aligned on a natural boundary. (The
size of the store address depends on the address-size attribute.) The most significant
bit in each byte of the mask operand determines whether the corresponding
byte in the source operand is written to the corresponding byte location in
memory: 0 indicates no write and 1 indicates write. The MASKMOVEDQU
instruction generates a non-temporal hint to the processor to minimize cache
pollution. The non-temporal hint is implemented by using a write combining
(WC) memory type protocol. Because the WC protocol uses a weakly-ordered
memory consistency model, a fencing operation implemented with the SFENCE or
MFENCE instruction should be used in conjunction with MASKMOVEDQU
instructions if multiple processors might use different memory types to
read/write the destination memory locations. Behavior with a mask
of all 0s is as follows: • No data will be
written to memory. • Signaling of
breakpoints (code or data) is not guaranteed; different processor
implementations may signal or not signal these breakpoints. • Exceptions associated
with addressing memory and page faults may still be signaled (implementation
dependent). • If the destination
memory region is mapped as UC or WP, enforcement of associated semantics for
these memory types is not guaranteed (that is, is reserved) and is
implementation- specific. The MASKMOVDQU
instruction can be used to improve performance of algorithms that need to
merge data on a byte-by-byte basis.
MASKMOVDQU should not cause a read for ownership; doing so generates
unnecessary bandwidth since data is to be written directly using the byte
mask without allocating old data prior to the store. |
||||||||||||||||||||||||
|
maskmovq |
Store Selected Bytes of Quad word. Mmx Instruction. |
|
Stores selected bytes
from the source operand (first operand) into a 64-bit memory location. The
mask operand (second operand) selects which bytes from the source operand are
written to memory. The source and mask operands are MMX registers. The
location of the first byte of the memory location is
specified by DI/EDI and DS registers. (The size of the store address depends
on the address-size attribute.) The most significant
bit in each byte of the mask operand determines whether the corresponding
byte in the source operand is written to the corresponding byte location in
memory: 0 indicates no write and 1 indicates write. The MASKMOVQ
instruction generates a non-temporal hint to the processor to minimize cache
pollution. The non-temporal hint is implemented by using a write combining
(WC) memory type protocol (see “Caching of Temporal vs. Non-Temporal Data” in
Chapter 10, of the IA-32 Intel
Architecture Software Developer’s Manual, Volume 1). Because the WC
protocol uses a weakly-ordered memory consistency model, a fencing operation
implemented with the SFENCE or MFENCE instruction should be used in
conjunction with MASKMOVEDQU instructions if multiple processors might use
different memory types to read/write the destination memory locations. This instruction
causes a transition from x87 FPU to MMX state (that is, the x87 FPU
top-of-stack pointer is set to 0 and the x87 FPU tag word is set to all 0s
[valid]). The behavior of the
MASKMOVQ instruction with a mask of all 0s is as follows: • No data will be
written to memory. • Transition from x87
FPU to MMX state will occur. • Exceptions associated
with addressing memory and page faults may still be signaled (implementation
dependent). • Signaling of
breakpoints (code or data) is not guaranteed (implementations dependent). • If the destination
memory region is mapped as UC or WP, enforcement of associated semantics for
these memory types is not guaranteed (that is, is reserved) and is
implementation-specific. The MASKMOVQ
instruction can be used to improve performance for algorithms that need to
merge data on a byte-by-byte basis. It should not cause a read for ownership;
doing so generates unnecessary bandwidth since data is to be written directly
using the byte-mask without allocating old data
prior to the store. |
||||||||||||||||||||||||
|
maxpd |
Return Maximum Packed Double-Precision
Floating-Point Values SSE/SSE2
Instruction |
|
Performs a SIMD
compare of the packed double precision floating-point values in the
destination operand (second operand) and the source operand (first operand),
and returns the maximum value for each pair of values to the destination
operand. The source operand can be an XMM register or a 128-bit memory
location. The destination operand is an XMM register. If the values being
compared are both 0.0s, the value in the source operand is returned. If a
value in the second operand is an SNaN, that SNaN is forwarded unchanged to
the destination (that is, a QNaN version of the SNaN is not returned). If only one value is a
NaN (SNaN or QNaN) for this instruction, the source operand, either a NaN or
a valid floating-point value, is written to the result. This behavior allows
compilers to use the MAXPD instruction for common C conditional constructs.
If instead of this behavior, it is required that the NaN source operand (from
either the first or second operand) be returned, the action of the MAXPD can
be emulated using a sequence of instructions, such as, a comparison followed
by AND, ANDN and OR. |
||||||||||||||||||||||||
|
maxps |
Return Maximum Packed
Single-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a SIMD
compare of the packed single-precision floating-point values in the
destination operand (second operand) and the source operand (first operand),
and returns the maximum value for each pair of values to the destination
operand. The source operand can be an XMM register or a 128-bit memory
location. The destination operand is an XMM register. If the values being
compared are both 0.0s, the value in the second operand (source operand) is
returned. If a value in the second operand is an SNaN, that SNaN is returned
unchanged to the destination (that is, a QNaN version of the SNaN is not
returned). If only one value is a
NaN (SNaN or QNaN) for this instruction, it is either a NaN or a valid
floating-point value, is written to the result. This behavior allows
compilers to use the MAXPS instruction for common C conditional constructs.
If instead of this behavior, it is required that the NaN source operand (from
either the first or second operand) be returned, the action of the MAXPS can
be emulated using a sequence of instructions, such as, a comparison followed
by AND, ANDN and OR. |
||||||||||||||||||||||||
|
maxsd |
Return Maximum Scalar
Double-Precision Floating-Point Value SSE/SSE2
Instruction |
|
Compares the low
double precision floating-point values in the destination operand (second
operand) and the source operand (first operand), and returns the maximum
value to the low quadword of the destination operand. The source operand can
be an XMM register or a 64-bit memory location. The destination operand is an
XMM register. When the source operand is a memory operand, only
64 bits are accessed. The high quadword of the destination operand remains
unchanged. If the values being
compared are both 0.0s, the value in the source operand is returned. If a value in the second
operand is an SNaN, that SNaN is returned unchanged to the destination (that
is, a QNaN version of the SNaN is not returned). If only one value is a
NaN (SNaN or QNaN) for this instruction, the first operand (source operand),
either a NaN or a valid floating-point value, is written to the result. This
behavior allows compilers to use the MAXSD instruction for common C
conditional constructs. If instead of this behavior, it is required that the
NaN source operand (from either the first or second operand) be returned,
the action of the MAXSD can be emulated using a sequence of instructions,
such as, a comparison followed by AND, ANDN and OR. |
||||||||||||||||||||||||
|
maxss |
Return Maximum Scalar
Single-Precision Floating-Point Value. SSE/SSE2
Instruction |
|
Compares the low
single-precision floating-point values in the destination operand (second
operand) and the source operand (first operand), and returns the maximum
value to the low double word of the destination operand. The source operand can
be an XMM register or a 32-bit memory location. The destination operand is an
XMM register. When the source operand is a memory operand, only 32 bits are
accessed. The three high-order double words of the destination operand remain
unchanged. If the values being
compared are both 0.0s, the value in the second operand (source operand) is
returned. If a value in the second operand is an SNaN, that SNaN is returned
unchanged to the destination (that is, a QNaN version of the SNaN is not
returned). If only one value is a
NaN (SNaN or QNaN) for this instruction, the source operand either a NaN or a valid floating-point
value, is written to the result. This behavior allows compilers to use the
MAXSS instruction for common C conditional constructs. If instead of this
behavior, it is required that the NaN source operand (from either the first
or second operand) be returned, the action of the MAXSS can be emulated using
a sequence of instructions, such as, a comparison followed by AND, ANDN and
OR. |
||||||||||||||||||||||||
|
mfence |
Memory Fence. |
|
Performs a serializing
operation on all load-from-memory and store-to-memory instructions that were
issued prior the MFENCE instruction. This serializing operation guarantees
that every load and store instruction that precedes in program order the
MFENCE instruction is globally visible before any load or store instruction
that follows the MFENCE instruction is globally visible. The MFENCE instruction is
ordered with respect to all load and store instructions, other MFENCE
instructions, any SFENCE and LFENCE instructions, and any serializing
instructions (such as the CPUID instruction). Weakly ordered memory
types can be used to achieve higher processor performance through such
techniques as out-of-order issue, speculative reads, write combining, and
write collapsing. The degree to which a consumer of data recognizes or knows
that the data is weakly ordered varies among
applications and may be unknown to the producer of this data. The MFENCE
instruction provides a performance-efficient way of ensuring load and store
ordering between routines that produce weakly ordered results and routines
that consume that data. It should be noted
that processors are free to speculatively fetch and cache data from system
memory regions that are assigned a memory-type that permits speculative reads
(that is, the WB, WC, and WT memory types). The PREFETCHh instruction is
considered a hint to this speculative behavior. Because this speculative
fetching can occur at any time and is not tied to instruction execution, the
MFENCE instruction is not ordered with respect to PREFETCHh instructions or any
other speculative fetching mechanism (that is, data could be speculative
loaded into the cache just before, during, or after the execution of an
MFENCE instruction). |
||||||||||||||||||||||||
|
minpd |
Return Minimum Packed
Double-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a SIMD
compare of the packed double precision floating-point values in the
destination operand (second operand) and the source operand (first operand),
and returns the minimum value for each pair of values to the destination
operand. The source operand can be an XMM register or a 128-bit memory
location. The destination operand is an XMM register. If the values being
compared are both 0.0s, the value in the source operand is returned. If a
value in the second operand is an SNaN, that SNaN is returned unchanged to
the destination (that is, a QNaN version of the SNaN is not returned). If only one value is a
NaN (SNaN or QNaN) for this instruction, the source operand, either a NaN or
a valid floating-point value, is written to the result. This behavior allows
compilers to use the MINPD instruction for common C conditional constructs.
If instead of this behavior, it is required that the NaN source operand (from
either the first or second operand) be returned, the action of the MINPD can
be emulated using a sequence of instructions, such as, a comparison
followed by AND, ANDN and OR. |
||||||||||||||||||||||||
|
minps |
Return Minimum Packed
Single-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a SIMD
compare of the packed single-precision floating-point values in the
destination operand (second operand) and the source operand (first operand),
and returns the minimum value for each pair of values to the destination
operand. The source operand can be an XMM register or a 128-bit memory
location. The destination operand is an XMM register. If the values being
compared are both 0.0s, the value in the first operand (source operand) is
returned. If a value in the second operand is an SNaN, that SNaN is returned
unchanged to the destination (that is, a QNaN version of the SNaN is not
returned). If only one value is a
NaN (SNaN or QNaN) for this instruction, the first operand (source operand),
either a NaN or a valid floating-point value, is written to the result. This
behavior allows compilers to use the MINPS instruction for common C
conditional constructs. If instead of this behavior, it is required that the
NaN source operand (from either the first or second operand) be returned,
the action of the MINPS can be emulated using a sequence of instructions,
such as, a comparison followed by AND, ANDN and OR. |
||||||||||||||||||||||||
|
minsd |
Return Minimum Scalar
Double-Precision Floating-Point Value. SSE/SSE2
Instruction |
|
Compares the low
double precision floating-point values in the destination operand (second
operand) and the source operand (first operand), and returns the minimum
value to the low quad word of the destination operand. The source operand can
be an XMM register or a 64-bit memory location. The destination operand is an
XMM register. When the source operand is a memory operand, only the 64 bits
are accessed. The high quad word of the destination operand remains
unchanged. If the values being
compared are both 0.0s, the value in the source operand is returned. If a
value in the second operand is an SNaN, that SNaN is returned unchanged to
the destination (that is, a QNaN version of the SNaN is not returned). If only one value is a
NaN (SNaN or QNaN) for this instruction, the source operand, either a NaN
or a valid floating-point value, is written to the result. This behavior
allows compilers to use the MINSD instruction for common C conditional
constructs. If instead of this behavior, it is required that the NaN source
operand (from either the first or second operand) be returned, the action of
the MINSD can be emulated using a sequence of instructions, such as, a
comparison followed by AND, ANDN and OR. |
||||||||||||||||||||||||
|
minss |
Return Minimum Scalar
Single-Precision Floating-Point Value. SSE/SSE2 Instruction |
|
Compares the low
single-precision floating-point values in the destination operand (second
operand) and the source operand (first operand), and returns the minimum
value to the low double word of the destination operand. The source operand
can be an XMM register or a 32-bit memory location. The
destination operand is an XMM register. When the source operand is a memory
operand, only 32 bits are accessed. The three high-order double words of the
destination operand remain unchanged. If the values being
compared are both 0.0s, the value in the first operand (source operand) is
returned. If a value in the second operand is an SNaN, that SNaN is returned
unchanged to the destination (that is, a QNaN version of the SNaN is not
returned). If only one value is a
NaN (SNaN or QNaN) for this instruction, the source operand, either a NaN or
a valid floating-point value, is written to the result. This behavior allows
compilers to use the MINSD instruction for common C conditional constructs.
If instead of this behavior, it is required that the NaN source operand (from
either the first or second operand) be returned, the action of the MINSD can
be emulated using a sequence of instructions, such as, a comparison followed
by AND, ANDN and OR. |
||||||||||||||||||||||||
|
mov |
Move data |
movl $4,%eax movs $5 %ax movb $5 %al |
Copies the first
operand (source operand) to the second operand (destination operand). The
source operand can be an immediate value, general-purpose register, segment
register, or memory location; the destination register can be a
general-purpose register, segment register, or memory location. Both operands
must be the same size, which can be a byte, a word, or a double word. The MOV instruction
cannot be used to load the CS register. Attempting to do so results in an
invalid opcode exception (#UD). To load the CS register, use the far JMP,
CALL, or RET instruction. If the destination operand is a segment register
(DS, ES, FS, GS, or SS), the source operand must be a valid segment selector.
In protected mode, moving a segment selector into a segment register
automatically causes the segment descriptor information associated with that
segment selector to be loaded into the hidden (shadow) part of the segment
register. While loading this information, the segment selector and segment
descriptor information is validated (see the “Operation” algorithm
below). The segment descriptor data is obtained from the GDT or LDT entry for
the specified segment selector. A null
segment selector (values 0000-0003) can be loaded into the DS, ES, FS, and GS
registers without causing a protection exception. However, any subsequent
attempt to reference a segment whose corresponding segment register is loaded
with a null value causes a general protection exception (#GP) and no memory
reference occurs. Loading the SS register with a MOV instruction inhibits all
interrupts until after the execution of the next instruction. This operation
allows a stack pointer to be loaded into the ESP register with the next
instruction (MOV ESP, stack-pointer
value) before an
interrupt occurs 1
. The LSS instruction
offers a more efficient method of loading the SS and ESP registers. When
operating in 32-bit mode and moving data between a segment register and a
general-purpose register, the 32-bit IA-32 processors do not require the use
of the 16-bit operand-size prefix (a byte with the value 66H) with this
instruction, but most assemblers will insert it if the standard form of the
instruction is used (for example, MOV DS, AX). The processor will execute
this instruction correctly, but it will usually require an extra clock. When
the processor executes the instruction with a 32-bit general-purpose
register, it assumes that the 16 least-significant bits of the
general-purpose register are the destination or source operand. If the
register is a destination operand, the resulting value in the two high-order
bytes of the register is implementation dependent. For the Pentium Pro
processor, the two high-order bytes are filled with zeros; for earlier 32-bit
IA-32 processors, the two high order bytes are undefined. |
||||||||||||||||||||||||
|
movapd |
Move Aligned Packed Double-Precision Floating-Point
Values SSE/SSE2
Instruction |
|
Moves a double quad
word containing two packed double-precision floating-point values from the
source operand (first operand) to the destination operand (second operand).
This instruction can be used to load an XMM register from a 128-bit memory
location, to store the contents of an XMM register into a 128-bit memory
location, or to move data between two XMM registers. When the source or
destination operand is a memory operand, the operand must be aligned on a
16-byte boundary or a general-protection exception (#GP) will be generated.
To move double-precision floating-point values to and from unaligned memory
locations, use the MOVUPD instruction. |
||||||||||||||||||||||||
|
movaps |
Move Aligned Packed Single-Precision Floating-Point
Values SSE/SSE2
Instruction |
|
Moves a double quad
word containing four packed single-precision floating-point values from the
source operand (first operand) to the destination operand (second operand).
This instruction can be used to load an XMM register from a 128-bit memory
location, to store the contents of an XMM register into a 128-bit memory
location, or to move data between two XMM registers. When the source or
destination operand is a memory operand, the operand must be aligned on a
16-byte boundary or a general-protection exception (#GP) is generated. To move packed
single-precision floating-point values to or from unaligned memory locations,
use the MOVUPS instruction. |
||||||||||||||||||||||||
|
movd |
Move Double word SSE/SSE2
Instruction |
|
Copies a double word
from the source operand (first operand) to the destination operand (second
operand). The source and destination operands can be general-purpose
registers, MMX registers, XMM registers, or 32-bit memory locations. This
instruction can be used to move a double-word to and from the low double word
an MMX register and a general-purpose register or a 32-bit memory location,
or to and from the low double word of an XMM register and a general-purpose
register or a 32-bit memory location. The instruction cannot be used to
transfer data between MMX registers, between XMM registers, between
general-purpose registers, or between memory locations. When the
destination operand is an MMX register, the source operand is written to the
low double word of the register, and the register is zero-extended to 64
bits. When the destination operand is an XMM register, the source operand is
written to the low double word of the register, and the register is
zero-extended to 128 bits. |
||||||||||||||||||||||||
|
movdqa |
Move Aligned Double Quad word. SSE/SSE2
Instruction |
|
Moves a double quad
word from the source operand (first operand) to the destination operand
(second operand). This instruction can be used to load an XMM register from a
128-bit memory location, to store the contents of an XMM register into a
128-bit memory location, or to move data between two XMM registers. When the
source or destination operand is a memory operand, the operand must be
aligned on a 16-byte boundary or a general-protection exception (#GP) will be
generated. To move a double quad
word to or from unaligned memory locations, use the MOVDQU instruction. |
||||||||||||||||||||||||
|
movdqu |
Move Unaligned Double Quad word. SSE/SSE2
Instruction |
|
Moves a double quad
word from the source operand (first operand) to the destination operand
(second operand). This instruction can be used to load an XMM register from a
128-bit memory location, to store the contents of an XMM register into a
128-bit memory location, or to move data between two XMM registers. When the
source or destination operand is a memory operand, the operand may be
unaligned on a 16-byte boundary without causing a general-protection
exception (#GP) to be generated. To move a double quad
word to or from memory locations that are known to be aligned on 16-byte
boundaries, use the MOVDQA instruction. While executing in
16-bit addressing mode, a linear address for a 128-bit data access that
over-laps the end of a 16-bit segment is not allowed and is defined as
reserved behavior. A specific processor implementation may or may not
generate a general-protection exception (#GP) in this situation, and the
address that spans the end of the segment may or may not wrap around to the
beginning of the segment. |
||||||||||||||||||||||||
|
movdq2q |
Move Quad word from XMM to MMX Register. SSE/SSE2
Instruction |
|
Moves the low quad
word from the source operand (first operand) to the destination operand
(second operand). The source operand is an XMM register and the destination
operand is an MMX register. This instruction
causes a transition from x87 FPU to MMX technology operation (that is, the
x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to
all 0s [valid]). If this instruction is executed while an x87 FPU
floating-point exception is pending, the exception is handled before the
MOVDQ2Q instruction is executed. |
||||||||||||||||||||||||
|
movhlps |
Move Packed Single-Precision Floating-Point Values
High to Low. SSE/SSE2
Instruction |
|
Moves two packed
single-precision floating-point values from the high quad word of the source
operand (first operand) to the low quad word of the destination operand
(second operand). The high quad word of the destination operand is left
unchanged. |
||||||||||||||||||||||||
|
movhpd |
Move High Packed Double-Precision Floating-Point
Value. SSE/SSE2
Instruction |
|
Moves a
double-precision floating-point value from the source operand (first operand)
to the destination operand (second operand). The source and destination
operands can be an XMM register or a 64-bit memory location. This instruction
allows a double-precision floating-point value to be moved to and from the
high quad word of an XMM register and memory. It cannot be used for register
to register or memory to memory moves. When the destination operand is an XMM
register, the low quad word of the register remains unchanged. |
||||||||||||||||||||||||
|
movhps |
Move High Packed Single-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Moves two packed
single-precision floating-point values from the source operand (first
operand) to the destination operand (second operand). The source and
destination operands can be an XMM register or a 64-bit memory location. This
instruction allows two single-precision floating-point values to be moved to
and from the high quad word of an XMM register and memory. It cannot be
used for register-to-register or memory to memory moves. When the destination
operand is an XMM register, the low quad word of the register remains unchanged. |
||||||||||||||||||||||||
|
movlhps |
Move Packed Single-Precision Floating-Point Values
Low to High. SSE/SSE2
Instruction |
|
Moves two packed
single-precision floating-point values from the low quad word of the source
operand (first operand) to the high quad word of the destination operand
(second operand). The high quad word of the destination operand is left
unchanged. |
||||||||||||||||||||||||
|
movlpd |
Move Low Packed Double-Precision Floating-Point
Value. SSE/SSE2
Instruction |
|
Moves a
double-precision floating-point value from the source operand (first operand)
to the destination operand (second operand). The source and destination
operands can be an XMM register or a 64-bit memory location. This instruction
allows a double-precision floating-point value to be moved to and from the
low quad word of an XMM register and memory. It cannot be used for
register-to-register or memory to memory moves. When the destination operand
is an XMM register, the high quad word of the register remains unchanged. |
||||||||||||||||||||||||
|
movlps |
Move Low Packed Single-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Moves two packed
single-precision floating-point values from the source operand (first
operand) and the destination operand (second operand). The source and
destination operands can be an XMM register or a 64-bit memory location. This
instruction allows two single-precision floating-point values to be moved to
and from the low quad word of an XMM register and memory. It cannot be used
for register-to-register or memory to memory moves. When the destination
operand is an XMM register, the high quad word of the register remains
unchanged. |
||||||||||||||||||||||||
|
movmskpd |
Extract Packed Double-Precision Floating-Point Sign
Mask. SSE/SSE2
Instruction |
|
Extracts the sign bits
from the packed double-precision floating-point values in the source operand
(first operand), formats them into a 2-bit mask, and stores the mask in the
destination operand (second operand). The source operand is an XMM register,
and the destination operand is a general-purpose register. The mask is stored
in the 2 low-order bits of the destination operand. |
||||||||||||||||||||||||
|
movmskps |
Extract Packed Single-Precision Floating-Point Sign
Mask. SSE/SSE2
Instruction |
|
Extracts the sign bits
from the packed single-precision floating-point values in the source operand
(first operand), formats them into a 4-bit mask, and stores the mask in the
destination operand (second operand). The source operand is an XMM register,
and the destination operand is a general-purpose register. The mask is stored
in the 4 low-order bits of the destination operand. |
||||||||||||||||||||||||
|
movntdq |
Store Double Quad word Using Non-Temporal Hint. SSE/SSE2
Instruction |
|
Moves the double quad
word in the source operand (first operand) to the destination operand (second
operand) using a non-temporal hint to prevent caching of the data during the
write to memory. The source operand is an XMM register, which is assumed to
contain integer data (packed bytes, words, double words, or quad words). The
destination operand is a 128-bit memory location. The non-temporal hint
is implemented by using a write combining (WC) memory type protocol when
writing the data to memory. Using this protocol, the processor does not write
the data into the cache hierarchy, nor does it fetch the corresponding cache
line from memory into the cache hierarchy. The memory type of the region
being written to can override the non-temporal hint, if the memory address
specified for the non-temporal store is in an uncacheable (UC) or write
protected (WP) memory region. Because the WC
protocol uses a weakly ordered memory consistency model, a fencing operation
implemented with the SFENCE or MFENCE instruction should be used in
conjunction with MOVNTDQ instructions if multiple processors might use
different memory types to read/write the destination memory locations. |
||||||||||||||||||||||||
|
movntq |
Store of Quad word Using Non-Temporal Hint. SSE/SSE2
Instruction |
|
Moves the quad word in
the source operand (second operand) to the destination operand (first
operand) using a non-temporal hint to minimize cache pollution during the
write to memory. The source operand is an MMX register, which is assumed to
contain packed integer data (packed bytes, words, or
double words). The destination operand is a 64-bit memory location. The
non-temporal hint is implemented by using a write combining (WC) memory type
protocol when writing the data to memory. Using this protocol, the processor
does not write the data into the cache hierarchy, nor does it fetch the
corresponding cache line from memory into the cache hierarchy.
The memory type of the region being written to can override the non-temporal
hint, if the memory address specified for the non-temporal store is in an
uncacheable (UC) or write protected (WP) memory region. |
||||||||||||||||||||||||
|
movnti |
Store Double word Using Non-Temporal Hint. Pentium 4 Instruction |
|
Moves the double word
integer in the source operand (first operand) to the destination operand
(second operand) using a non-temporal hint to minimize cache pollution during
the write to memory. The source operand is a general-purpose register. The
destination operand is a 32-bit memory location. The non-temporal hint
is implemented by using a write combining (WC) memory type protocol when
writing the data to memory. Using this protocol, the processor does not write
the data into the cache hierarchy, nor does it fetch the corresponding cache
line from memory into the cache hierarchy. The memory type of the region
being written to can override the non-temporal hint, if the memory address
specified for the non-temporal store is in an uncacheable (UC) or write
protected (WP) memory region. Because the WC
protocol uses a weakly ordered memory consistency model, a fencing operation
implemented with the SFENCE or MFENCE instruction should be used in
conjunction with MOVNTI instructions if multiple processors might use
different memory types to read/write the destination memory locations. |
||||||||||||||||||||||||
|
movntpd |
Store Packed Double-Precision Floating-Point Values
Using Non-Temporal Hint. SSE/SSE2
Instruction |
|
Moves the double quad
word in the source operand (first operand) to the destination operand (second
operand) using a non-temporal hint to minimize cache pollution during the
write to memory. The source operand is an XMM register, which is assumed to
contain two packed double-precision floating-point values. The destination
operand is a 128-bit memory location. The non-temporal hint is implemented by
using a write combining (WC) memory type protocol when writing the data to
memory. Using this protocol, the processor does not write the data into the
cache hierarchy, nor does it fetch the corresponding cache line from memory
into the cache hierarchy. The memory type of the region being written to can
override the non-temporal hint, if the memory address
specified for the non-temporal store is in an uncacheable (UC) or write
protected (WP) memory region. Because the WC
protocol uses a weakly ordered memory consistency model, a fencing operation
implemented with the SFENCE or MFENCE instruction should be used in
conjunction with MOVNTPD instructions if multiple processors might use
different memory types to read/write the destination memory locations. |
||||||||||||||||||||||||
|
movntps |
Store Packed Single-Precision Floating-Point Values
Using Non-Temporal Hint. SSE/SSE2
Instruction |
|
Moves the double quad
word in the source operand (first operand) to the destination operand (second
operand) using a non-temporal hint to minimize cache pollution during the
write to memory. The source operand is an XMM register, which is assumed to
contain four packed single-precision floating-point values. The destination
operand is a 128-bit memory location. The non-temporal hint
is implemented by using a write combining (WC) memory type protocol when
writing the data to memory. Using this protocol, the processor does not write
the data into the cache hierarchy, nor does it fetch the corresponding cache
line from memory into the cache hierarchy. The memory type of the region
being written to can override the non-temporal hint, if the memory address
specified for the non-temporal store is in an uncacheable (UC) or write
protected (WP) memory region. Because the WC
protocol uses a weakly ordered memory consistency model, a fencing operation
implemented with the SFENCE or MFENCE instruction should be used in
conjunction with MOVNTPS instructions if multiple processors might use
different memory types to read/write the destination memory locations. |
||||||||||||||||||||||||
|
movntq |
Store of Quad word Using Non-Temporal Hint. MMX Instruction |
|
See movntps. |
||||||||||||||||||||||||
|
movq |
Move Quad word MMX
Instruction SSE/SSE2
Instruction |
|
Copies a quad word
from the source operand (second operand) to the destination operand (first
operand). The source and destination operands can be MMX registers, XMM
registers, or 64-bit memory locations. This instruction can be used to move a
quad word between two MMX registers or between an MMX register and a 64-bit
memory location, or to move data between two XMM registers or between an XMM
register and a 64-bit memory location. The instruction cannot be used to
transfer data between memory locations. When the
source operand is an XMM register, the low quad word is moved; when the
destination operand is an XMM register, the quad word is stored to the low
quad word of the register, and the high quad word is cleared to all 0s. |
||||||||||||||||||||||||
|
movq2dq |
Move Quad word from MMX to XMM Register. SSE/SSE2
Instruction MMX
Instruction |
|
Moves the quad word
from the source operand (first operand) to the low quad word of the
destination operand (second operand). The source operand is an MMX register
and the destination operand is an XMM register. This instruction
causes a transition from x87 FPU to MMX technology operation (that is, the
x87 FPU top-of-stack pointer is set to 0 and the x87 FPU tag word is set to
all 0s [valid]). If this instruction is executed while an x87 FPU
floating-point exception is pending, the exception is handled before the
MOVQ2DQ instruction is executed. |
||||||||||||||||||||||||
|
movs |
Move Data from String to String |
|
Moves the byte, word,
or double word specified with the first operand (source operand) to the
location specified with the second operand (destination operand). Both the
source and destination operands are located in memory. The address of the
source operand is read from the DS:ESI or the DS:SI registers
(depending on the address-size attribute of the instruction, 32 or 16,
respectively). The address of the
destination operand is read from the ES:EDI or the ES:DI registers (again
depending on the address-size attribute of the instruction). The DS segment
may be over-ridden with a segment override prefix, but the ES segment cannot
be overridden. The locations of the
source and destination operands are always specified by the DS:(E)SI and ES:(E)DI
registers, which must be loaded correctly before the move string instruction
is executed. The no-operands form
provides “short forms” of the byte, word, and double word versions of the
MOVS instructions. Here also DS:(E)SI and ES:(E)DI are assumed to be the
source and destination operands, respectively. The size of the source and
destination operands is selected with the mnemonic: MOVSB (byte move), MOVSW
(word move), or MOVSD (double word move). After the move
operation, the (E)SI and (E)DI registers are incremented or decremented
automatically according to the setting of the DF flag in the EFLAGS register.
(If the DF flag is 0, the (E)SI and (E)DI register are incremented; if the DF
flag is 1, the (E)SI and (E)DI registers are decremented.) The registers are
incremented or decremented by 1 for byte operations, by 2 for word
operations, or by 4 for double word operations. The MOVS,
MOVSB, MOVSW, and MOVSD instructions can be preceded by the REP prefix (see
“REP/REPE/REPZ/REPNE /REPNZ—Repeat String Operation Prefix”) for block moves
of ECX bytes, words, or double words. |
||||||||||||||||||||||||
|
movsbl |
|
||||||||||||||||||||||||||
|
movsbw |
|
||||||||||||||||||||||||||
|
movswl |
|
||||||||||||||||||||||||||
|
movsd |
Move Scalar Double-Precision Floating-Point Value. SSE/SSE2
Instruction |
|
Moves a scalar double-precision floating-point value from the
source operand (first operand) to the destination operand (first operand).
The source and destination operands can be XMM registers or 64-bit memory
locations. This instruction can be used to move a double-precision
floating-point value to and from the low quad word of an XMM register and a
64-bit memory location, or to move a double-precision floating-point value
between the low quad words of two XMM registers. The instruction cannot be
used to transfer data between memory locations. When the source and
destination operands are XMM registers, the high quad word of the destination
operand remains unchanged. When the source operand is a memory location and
destination operand is an XMM registers, the high quad word of the
destination operand is cleared to all 0s. |
||||||||||||||||||||||||
|
movss |
Move Scalar Single--Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Moves a
scalar single-precision floating-point value from the source operand (first
operand) to the destination operand (second operand). The source and
destination operands can be XMM registers or 32-bit memory locations. This
instruction can be used to move a single-precision floating-point value to
and from the low double word of an XMM register and a 32-bit memory location,
or to move a single-precision floating-point value between the low double
words of two XMM registers. The instruction cannot be used to transfer data
between memory locations. When the source and destination operands are XMM
registers, the three high-order double words of the destination operand
remain unchanged. When the source operand is a memory location and
destination operand is an XMM registers, the three high-order double words of
the destination operand are cleared to all 0s. |
||||||||||||||||||||||||
|
movupd |
Move Unaligned Packed Double-Precision Floating-Point Values. SSE/SSE2 Instruction |
|
Moves a
double quad word containing two packed double-precision floating-point values
from the source operand (first operand) to the destination operand (second
operand). This instruction can be used to load an XMM register from a 128-bit
memory location, to store the contents of an XMM register into a 128-bit
memory location, or move data between two XMM registers. When the
source or destination operand is a memory operand, the operand may be
unaligned on a 16-byte boundary without causing a general-protection
exception (#GP) to be generated. To move
double-precision floating-point values to and from memory locations that are
known to be aligned on 16-byte boundaries, use the MOVAPD instruction. While
executing in 16-bit addressing mode, a linear address for a 128-bit data
access that over-laps the end of a 16-bit segment is not allowed and is
defined as reserved behavior. A specific processor implementation may or may
not generate a general-protection exception (#GP) in this situation, and the
address that spans the end of the segment may or may not wrap around to the
beginning of the segment. |
||||||||||||||||||||||||
|
movups |
Move Unaligned Packed Single-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Moves a double quad
word containing four packed single-precision floating-point values from the
source operand (first operand) to the destination operand (second operand).
This instruction can be used to load an XMM register from a 128-bit memory
location, to store the contents of an XMM register into a 128-bit memory location,
or move data between two XMM registers. When the source or
destination operand is a memory operand, the operand may be unaligned on a
16-byte boundary without causing a general protection exception (#GP) to be
generated. To move packed single-precision floating-point values to and from
memory locations that are known to be aligned on 16-byte boundaries, use the
MOVAPS instruction. While
executing in 16-bit addressing mode, a linear address for a 128-bit data
access that over-laps the end of a 16-bit segment is not allowed and is
defined as reserved behavior. A specific processor implementation may or may
not generate a general-protection exception (#GP) in this situation, and the
address that spans the end of the segment may or may not wrap around to the
beginning of the segment. |
||||||||||||||||||||||||
|
movzb |
Move with Zero-Extend |
|
Copies the
contents of the source operand (register or memory location) to the
destination operand (register) and zero extends the value to 16 or 32 bits.
The size of the converted value depends on the operand-size attribute. |
||||||||||||||||||||||||
|
movzwl |
|
||||||||||||||||||||||||||
|
mul |
Unsigned Multiply |
|
Performs an
unsigned multiplication of the second operand (destination operand) and the
first operand (source operand) and stores the result in the destination
operand. The destination operand is an implied operand located in register
AL, AX or EAX (depending on the size of the operand); the source operand is
located in a general-purpose register or a memory location. The action of
this instruction and the location of the result depends on the opcode and the
operand size as shown in the following table. The result is stored
in register AX, register pair DX:AX, or register pair EDX:EAX (depending on
the operand size), with the high-order bits of the product contained in
register AH, DX, or EDX, respectively. If the high-order bits of the product
are 0, the CF and OF flags are cleared;
otherwise,
the flags are set.
|
||||||||||||||||||||||||
|
mulpd |
Multiply Packed Double-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Performs a
SIMD multiply of the two packed double-precision floating-point values from
the source operand (first operand) and the destination operand (second operand),
and stores the packed double-precision floating-point results in the
destination operand. The source operand can be an XMM register or a 128-bit
memory location. The destination operand is an XMM register. The mulps opcode denotes the same operation
but in single precision. |
||||||||||||||||||||||||
|
mulps |
Multiply Packed Single-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
|||||||||||||||||||||||||
|
mulsd |
Multiply Scalar Double-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Multiplies the low
double-precision floating-point value in the source operand (first operand)
by the low double-precision floating-point value in the destination operand
(second operand), and stores the double precision floating-point result in
the destination operand. The source operand can be an XMM register or a
64-bit memory location. The destination operand is an XMM register. The high
quad word of the destination operand remains unchanged. |
||||||||||||||||||||||||
|
mulss |
Multiply Scalar Single-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Multiplies the low
single-precision floating-point value from the source operand (first operand)
by the low single-precision floating-point value in the destination operand
(second operand), and stores the single-precision floating-point result in
the destination operand. The source operand can be an XMM register or a
32-bit memory location. The destination operand is an XMM register.
The three high-order double words of the destination operand remain
unchanged. |
||||||||||||||||||||||||
|
neg |
Two’s Complement Negation |
|
Replaces
the value of operand (the destination operand) with its two’s complement.
(This operation is equivalent to subtracting the operand from 0.) The
destination operand is located in a general-purpose register or a memory
location. This instruction can be used with a LOCK prefix to allow the instruction
to be executed atomically. |
||||||||||||||||||||||||
|
nop |
No Operation |
|
Performs no
operation. This instruction is a one-byte instruction that takes up space in
the instruction stream but does not affect the machine context, except the
EIP register. The NOP instruction is an alias mnemonic for the XCHG (E)AX,
(E)AX instruction. |
||||||||||||||||||||||||
|
not |
One’s Complement
Negation |
|
Performs a bitwise NOT
operation (each 1 is cleared to 0, and each 0 is set to 1) on the destination
operand and stores the result in the destination operand location. The destination
operand can be a register or a memory location. This
instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically. |
||||||||||||||||||||||||
|
or |
Logical
Inclusive OR |
|
Performs a bitwise
inclusive OR operation between the destination (second) and source (first)
operands and stores the result in the destination operand location. The
source operand can be an immediate, a register, or a memory location; the
destination operand can be a register or a memory location. (However, two
memory operands cannot be used in one instruction.) Each bit of the result of
the OR instruction is set to 0 if both corresponding bits of the first and
second operands are 0; otherwise, each bit is set to 1. This
instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically. |
||||||||||||||||||||||||
|
orpd |
Bitwise Logical
OR of Double-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a bitwise
logical OR of the two packed double precision floating-point values from the
source operand (first operand) and the destination operand (second operand),
and stores the result in the destination operand. The source operand can be
an XMM register or a 128-bit memory location. The destination operand is an
XMM register. |
||||||||||||||||||||||||
|
orps |
Bitwise Logical OR of Single-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Performs a bitwise
logical OR of the four packed single-precision floating-point values from the
source operand (first operand) and the destination operand (second operand),
and stores the result in the destination operand. The source operand can be
an XMM register or a 128-bit memory location. The destination operand is an
XMM register. |
||||||||||||||||||||||||
|
out |
Output to Port |
|
Copies the value from
the first operand (source operand) to the I/O port specified with the
destination operand (second operand). The source operand can be register AL,
AX, or EAX, depending on the size of the port being accessed (8, 16, or 32
bits, respectively); the destination operand can be a byte-immediate or the
DX register. Using a byte immediate allows I/O port addresses 0 to 255 to be
accessed; using the DX register as a source operand allows I/O ports from 0
to 65,535 to be accessed. The size of
the I/O port being accessed is determined by the opcode for an 8-bit I/O port
or by the operand-size attribute of the instruction for a 16- or 32-bit I/O
port. At the machine code level, I/O
instructions are shorter when accessing 8-bit I/O ports. Here, the upper
eight bits of the port address will be 0. |
||||||||||||||||||||||||
|
outs |
Output String to Port |
|
Copies data from the
source operand (first operand) to the I/O port specified with the destination
operand (second operand). The source operand is a memory location, the
address of which is read from either the DS:EDI or the DS:DI registers
(depending on the address-size attribute of the
instruction, 32 or 16, respectively). (The DS segment may be overridden with
a segment override prefix.) The destination operand is an I/O port address
(from 0 to 65,535) that is read from the DX register. The size of the I/O
port being accessed (that is, the size of the source and destination
operands) is determined by the opcode for an 8-bit I/O port or by the
operand-size attribute of the instruction for a 16- or 32-bit I/O port. |
||||||||||||||||||||||||
|
packssdw |
Pack with Signed Saturation. SSE/SSE2
Instruction MMX
Instruction |
|
Converts
packed signed/unsigned word integers into packed signed byte integers
(PACKSSWB) or converts packed signed double word integers into packed signed
word integers (PACKSSDW), using saturation to handle overflow conditions. See
Figure for an example of the packing operation.
|
||||||||||||||||||||||||
|
packsswb |
|
||||||||||||||||||||||||||
|
packuswb |
|
||||||||||||||||||||||||||
|
paddb |
Add Packed Integers SSE/SSE2 Instruction MMX Instruction |
|
Performs a SIMD add of
the packed integers from the source operand (first operand) and the
destination operand (second operand), and stores the packed integer results
in the destination operand. Overflow is handled with wraparound, as described
in the following paragraphs. These instructions can
operate on either 64-bit or 128-bit operands. When operating on 64-bit
operands, the destination operand must be an MMX register and the source
operand can be either an MMX register or a 64-bit memory location. When
operating on 128-bit operands, the destination operand must be an XXM
register and the source operand can be either an XMM register or a 128-bit
memory location. The PADDB instruction
adds packed byte integers. When an individual result is too large to be
represented in 8 bits (overflow), the result is wrapped around and the low 8
bits are written to the destination operand (that is, the carry is ignored). The PADDW instruction
adds packed word integers. When an individual result is too large to be
represented in 16 bits (overflow), the result is wrapped around and the low
16 bits are written to the destination operand. The PADDD
instruction adds packed double word integers. When an individual result is
too large to be represented in 32 bits (overflow), the result is wrapped
around and the low 32 bits are written to the destination operand. Note that
the PADDB, PADDW, and PADDD instructions can operate on either unsigned or
signed (two’s complement notation) packed integers; however, it does not set
bits in the EFLAGS register to indicate overflow and/or a carry. To prevent
undetected overflow conditions, software must control the ranges of values
operated on. |
||||||||||||||||||||||||
|
paddd |
|
||||||||||||||||||||||||||
|
paddsb |
|
||||||||||||||||||||||||||
|
paddsw paddq |
|
||||||||||||||||||||||||||
|
paddusb |
Add Packed Unsigned Integers with Unsigned
Saturation. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD add of
the packed unsigned integers from the source operand (first operand) and the destination
operand (second operand), and stores the packed integer results in the
destination operand. Overflow is handled with unsigned saturation, as
described in the following paragraphs. These instructions can
operate on either 64-bit or 128-bit operands. When operating on 64-bit
operands, the destination operand must be an MMX register and the source
operand can be either an MMX register or a 64-bit memory location. When
operating on 128-bit operands, the destination operand must be an XXM
register and the source operand can be either an XMM register or a 128-bit
memory location. The PADDUSB
instruction adds packed unsigned byte integers. When an individual byte
result is beyond the range of an unsigned byte integer (that is, greater than
FFH), the saturated value of FFH is written to the destination operand. The
PADDUSW instruction adds packed unsigned word integers. When an individual
word result is beyond the range of an unsigned word integer (that is, greater
than FFFFH), the saturated value of FFFFH is written to the destination
operand. |
||||||||||||||||||||||||
|
paddusw |
|
||||||||||||||||||||||||||
|
paddw |
|
|
|
||||||||||||||||||||||||
|
pand |
Logical AND SSE/SSE2 Instruction MMX Instruction |
|
Performs a bitwise
logical AND operation on the source operand (first operand) and the
destination operand (second operand) and stores the result in the destination
operand. The source operand can be an MMX register or a 64-bit memory
location or it can be an XMM register or a 128-bit memory
location. The destination operand can be an MMX register or an XMM register.
Each bit of the result is set to 1 if the corresponding bits of the first and
second operands are 1;
otherwise, it is set to 0. |
||||||||||||||||||||||||
|
pandn |
Logical AND NOT SSE/SSE2
Instruction MMX
Instruction |
|
Performs a bitwise
logical NOT of the destination operand (second operand), then performs a bitwise
logical AND of the source operand (first operand) and the inverted
destination operand. The result is stored in the destination operand. The
source operand can be an MMX register or a 64-bit memory location or it can
be an XMM register or a 128-bit memory location. The
destination operand can be an MMX register or an XMM register. Each bit of
the result is set to 1 if the corresponding bit in the first operand is 0 and
the corresponding bit in the second operand is 1; otherwise, it is set to 0. |
||||||||||||||||||||||||
|
pause |
Spin Loop Hint Pentium4 extension. |
|
Improves the
performance of spin-wait loops. When executing a “spin-wait loop,” a Pentium
4 processor suffers a severe performance penalty when exiting the loop
because it detects a possible memory order violation. The PAUSE instruction
provides a hint to the processor that the code sequence is a spin-wait loop.
The processor uses this hint to bypass the memory order violation in most
situations, which greatly improves processor performance. For this reason, it
is recommended that a PAUSE instruction be placed in all spin-wait loops. An
additional function of the PAUSE instruction is to reduce the power consumed
by a Pentium 4 processor while executing a spin loop. The Pentium 4 processor
can execute a spin-wait loop extremely quickly; causing the processor to
consume a lot of power while it waits for the resource it is spinning on to
become available. Inserting a pause instruction in a spin-wait loop greatly
reduces the processor’s power consumption. This instruction was introduced
in the Pentium 4 processors, but is backward compatible with all IA-32
processors. In earlier IA-32 processors, the PAUSE instruction operates like
a NOP instruction. The Pentium 4
processor implements the PAUSE instruction as a pre-defined delay. The delay
is finite and can be zero for some processors. This instruction does not
change the architectural state of the processor (that is, it performs
essentially a delaying no-op operation). |
||||||||||||||||||||||||
|
pavgb pavgw |
Average Packed Integers SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
average of the packed unsigned integers from the source operand (first
operand) and the destination operand (second operand), and stores the results
in the destination operand. For each corresponding pair of data elements in the
first and second operands, the elements are added together, a 1 is added to
the temporary sum, and that result is shifted right one bit position. The
source operand can be an MMX register or a 64-bit memory location or it can
be an XMM register or a 128-bit memory location. The destination operand can
be an MMX register or an XMM register. The PAVGB
instruction operates on packed unsigned bytes and the PAVGW instruction
operates on packed unsigned words. |
||||||||||||||||||||||||
|
pavgusb |
|
|
|
||||||||||||||||||||||||
|
pcmpeqb |
Compare
Packed Data for Equal. SSE/SSE2 Instruction MMX Instruction |
|
Performs a SIMD
compare for equality of the packed bytes, words, or double words in the
destination operand (second operand) and the source operand (first operand).
If a pair of data elements is equal, the corresponding data element in the
destination operand is set to all 1s; otherwise, it is set to all 0s. The
source operand can be an MMX register or a 64-bit memory location, or it can
be an XMM register or a 128-bit memory location. The destination operand can
be an MMX or an XMM register. The PCMPEQB
instruction compares the corresponding bytes in the destination and source
operands; the PCMPEQW instruction compares the corresponding words in the
destination and source operands; and the PCMPEQD instruction compares the
corresponding double words in the destination and source operands. |
||||||||||||||||||||||||
|
pcmpeqd |
|
||||||||||||||||||||||||||
|
pcmpeqw |
|
||||||||||||||||||||||||||
|
pcmpgtb |
Compare
Packed Data for Greater Than. SSE/SSE2 Instruction MMX Instruction |
|
Performs a SIMD signed
compare for the greater value of the packed byte, word, or double word
integers in the destination operand (second operand) and the source operand
(first operand). If a data element in the destination operand is greater than
the corresponding date element in the source operand, the corresponding data
element in the destination operand is set to all 1s; otherwise, it is set to
all 0s. The source operand can be an MMX register or a 64-bit memory
location, or it can be an XMM register or a 128-bit memory location. The
destination operand can be an MMX or an XMM register. The PCMPGTB
instruction compares the corresponding signed byte integers in the destination and source operands; the PCMPGTW
instruction compares the corresponding signed word integers in the
destination and source operands; and the PCMPGTD instruction compares the
corresponding signed double word integers in the destination and source
operands. |
||||||||||||||||||||||||
|
pcmpgtd |
|
||||||||||||||||||||||||||
|
pcmpgtw |
|
||||||||||||||||||||||||||
|
pf2id |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pf2iw |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfacc |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfadd |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfcmpeq |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfcmpge |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfcmpgt |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfmax |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfmin |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfmul |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfnacc |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfpnacc |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfrcp |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfrcpit1 |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfrcpit2 |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfrsqit1 |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfrsqrt |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfsub |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pfsubr |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pi2fd |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pi2fw |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pmaddwd |
Multiply and Add Packed Integers. SSE/SSE2
Instruction MMX
Instruction |
|
Multiplies the
individual signed words of the destination operand (second operand) by the
corresponding signed words of the source operand (first operand), producing
temporary signed, double word results. The adjacent double word results are
then summed and stored in the destination operand. For example, the
corresponding low-order words (15-0) and (31-16) in the source and
destination operands are multiplied by one another and the double word
results are added together and stored in the low double word of the
destination register (31-0). The same operation is performed on the other
pairs of adjacent words. (Figure 3-6 shows this operation when using 64-bit
operands.) The source operand can be an MMX register or a 64-bit memory
location, or it can be an XMM register or a 128-bit memory location. The
destination operand can be an MMX or an XMM register. The PMADDWD
instruction wraps around only in one situation: when the 2 pairs of words
being operated on in a group are all 8000H. In this case, the result wraps
around to 80000000H. |
||||||||||||||||||||||||
|
pmaxsw |
Maximum of Packed Signed Word Integers. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
compare of the packed signed word integers in the destination operand (second
operand) and the source operand (first operand), and returns the maximum
value for each pair of word integers to the destination operand. The source
operand can be an MMX register or a 64-bit
memory location, or it can be an XMM register or a 128-bit memory location.
The destination operand can be an MMX or an XMM register. |
||||||||||||||||||||||||
|
pmaxub |
Maximum of Packed Unsigned Byte Integers. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
compare of the packed unsigned byte integers in the destination operand
(second operand) and the source operand (first operand), and returns the
maximum value for each pair of byte integers to the destination operand. The
source operand can be an MMX register or a 64-bit memory location, or it
can be an XMM register or a 128-bit memory location. The destination operand
can be an MMX or an XMM register. |
||||||||||||||||||||||||
|
pminsw |
Minimum of Packed Signed Word Integers. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
compare of the packed signed word integers in the destination operand (second
operand) and the source operand (first operand), and returns the minimum
value for each pair of word integers to the destination operand. The source
operand can be an MMX register or a 64-bit memory
location, or it can be an XMM register or a 128-bit memory location. The
destination operand can be an MMX or an XMM register. |
||||||||||||||||||||||||
|
pminub |
Minimum of Packed Unsigned Byte Integers. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
compare of the packed unsigned byte integers in the destination operand
(second operand) and the source operand (first operand), and returns the
minimum value for each pair of byte integers to the destination operand. The
source operand can be an MMX register or a 64-bit memory location, or it can
be an XMM register or a 128-bit memory location. The destination operand can
be an MMX or an XMM register. |
||||||||||||||||||||||||
|
pmovmskb |
Move Byte Mask. SSE/SSE2
Instruction MMX
Instruction |
|
Creates a mask made up
of the most significant bit of each byte of the source operand (first
operand) and stores the result in the low byte or word of the destination
operand (second operand). The source operand is
an MMX or an XXM register; the destination operand is a general-purpose
register. When operating on 64-bit operands, the byte mask is 8 bits; when
operating on 128-bit operands, the byte mask is 16-bits. |
||||||||||||||||||||||||
|
pmulhuw |
Multiply Packed Unsigned Integers and Store High Result SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
unsigned multiply of the packed unsigned word integers in the destination
operand (second operand) and the source operand (first operand), and stores
the high 16 bits of each 32-bit intermediate results in the destination
operand. The source operand can be an MMX register or a 64-bit memory
location, or it can be an XMM register or a 128-bit memory location. The
destination operand can be an MMX or an XMM register. |
||||||||||||||||||||||||
|
pmulhrw |
Amd3DNow |
|
|
||||||||||||||||||||||||
|
pmulhw |
Multiply Packed Signed Integers and Store High Result. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a
SIMD signed multiply of the packed signed word integers in the destination
operand (second operand) and the source operand (first operand), and stores
the high 16 bits of each intermediate 32-bit result in the destination
operand. The source operand can be an MMX register or a 64-bit memory
location, or it can be an XMM register or a 128-bit memory location. The
destination operand can be an MMX or an XMM register. |
||||||||||||||||||||||||
|
pmullw |
Multiply Packed Signed Integers and Store Low Result. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD signed multiply of the packed signed word
integers in the destination operand (second operand) and the source operand
(first operand), and stores the low 16 bits of each intermediate 32-bit
result in the destination operand. The source operand can be an MMX register
or a 64-bit memory location, or it can be an XMM register or a 128-bit memory
location. The destination operand can be an MMX or an XMM register. |
||||||||||||||||||||||||
|
pmuludq |
Multiply Packed Unsigned Double word Integers. SSE/SSE2
Instruction MMX
Instruction |
|
Multiplies the second
operand (destination operand) by the first operand (source operand) and
stores the result in the destination operand. The source operand can be a
unsigned double word integer stored in the low double word of an MMX register
or a 64-bit memory location, or it can be two packed unsigned double word
integers stored in the first (low) and third double words of an XMM register
or an 128-bit memory location. The destination operand can be a unsigned
double word integer stored in the low double word an MMX register or two
packed double word integers stored in the first and third double words of an
XMM register. The result is an unsigned quad word integer stored in the
destination an MMX register or two packed unsigned quad word integers stored
in an XMM register. When a quad word result is too large to be represented in
64 bits (overflow), the result is wrapped around and the low 64 bits are
written to the destination element (that is, the carry is ignored). For 64-bit
memory operands, 64 bits are fetched from memory, but only the low double
word is used in the computation; for 128-bit memory operands, 128 bits are
fetched from memory, but only the first and third double words are used in
the computation. |
||||||||||||||||||||||||
|
pop |
Pop a Value from the Stack |
|
Loads the value from
the top of the stack to the location specified with the destination operand
and then increments the stack pointer. The destination operand can be a
general-purpose register, memory location, or segment register. The address-size
attribute of the stack segment determines the stack pointer size (16 bits or
32 bits—the source address size), and the operand-size attribute of the
current code segment deter-mines the amount the stack pointer is incremented
(2 bytes or 4 bytes). For example, if these address- and operand-size
attributes are 32, the 32-bit ESP register (stack pointer) is incremented by
4 and, if they are 16, the 16-bit SP register is incremented by 2. (The B
flag in the stack segment’s segment descriptor determines the stack’s
address-size attribute, and the D flag in the current code segment’s segment
descriptor, along with prefixes, determines the operand-size attribute and
also the address-size attribute of the destination operand.) If the destination
operand is one of the segment registers DS, ES, FS, GS, or SS, the value
loaded into the register must be a valid segment selector. In protected mode,
popping a segment selector into a segment register automatically causes the
descriptor information associated with that segment selector to be loaded
into the hidden (shadow) part of the segment register and causes the selector
and the descriptor information to be validated. A null value
(0000-0003) may be popped into the DS, ES, FS, or GS register without causing
a general protection fault. However, any subsequent attempt to reference a
segment whose corresponding segment register is loaded with a null value
causes a general protection exception (#GP). In this situation, no memory
reference occurs and the saved value of the segment register is null. The POP instruction
cannot pop a value into the CS register. To load the CS register from the
stack, use the RET instruction. If the ESP
register is used as a base register for addressing a destination operand in
memory, the POP instruction computes the effective address of the operand
after it increments the ESP register. For the case of a 16-bit stack where
ESP wraps to 0h as a result of the POP instruction, the resulting location of
the memory write is processor-family-specific. |
||||||||||||||||||||||||
|
popa |
Pop All General-Purpose Registers |
|
Pops double words (POPAD)
or words (POPA) from the stack into the general-purpose registers. The registers are
loaded in the following order: EDI, ESI, EBP, EBX, EDX, ECX, and EAX (if the
operand-size attribute is 32) and DI, SI, BP, BX, DX, CX, and AX (if the
operand-size attribute is 16). (These instructions reverse the operation of
the PUSHA/PUSHAD instructions.) The value on the stack
for the ESP or SP register is ignored. Instead, the ESP or SP register is
incremented after each register is loaded. The POPA
(pop all) and POPAD (pop all double) mnemonics reference the same opcode. The
POPA instruction is intended for use when the operand-size attribute is 16
and the POPAD instruction for when the operand-size attribute is 32. Some
assemblers may force the operand size to 16 when POPA is used and to 32 when
POPAD is used (using the operand-size override prefix [66H] if necessary).
Others may treat these mnemonics as synonyms (POPA/POPAD) and use the current
setting of the operand-size attribute to determine the size of values to be
popped from the stack, regardless of the mnemonic used. (The D flag in the
current code segment’s segment descriptor determines the operand-size
attribute.) |
||||||||||||||||||||||||
|
popf |
Pop Stack into EFLAGS Register |
|
Pops a double word
(POPFD) from the top of the stack (if the current operand-size attribute is
32) and stores the value in the EFLAGS register, or pops a word from the top
of the stack (if the operand-size attribute is 16) and stores it in the lower
16 bits of the EFLAGS register (that is, the FLAGS register). These
instructions reverse the operation of the PUSHF/PUSHFD instructions. The POPF (pop flags)
and POPFD (pop flags double) mnemonics reference the same opcode. The POPF instruction
is intended for use when the operand-size attribute is 16 and the POPFD instruction
for when the operand-size attribute is 32. Some assemblers may force the
operand size to 16 when POPF is used and to 32 when POPFD is used. Others may
treat these mnemonics as synonyms (POPF/POPFD) and use the current setting of
the operand-size attribute to determine the size of values to be popped from
the stack, regardless of the mnemonic used. The effect of the
POPF/POPFD instructions on the EFLAGS register changes slightly, depending on
the mode of operation of the processor. When the processor is operating in
protected mode at privilege level 0 (or in real-address mode, which is
equivalent to privilege level 0), all the non-reserved flags in the EFLAGS
register except the VIP, VIF, and VM flags can be modified. The
VIP and VIF flags are cleared, and the VM flag is unaffected. When operating in
protected mode, with a privilege level greater than 0, but less than or equal
to IOPL, all the flags can be modified except the IOPL field and the VIP,
VIF, and VM flags. Here, the IOPL flags are unaffected, the VIP and VIF flags
are cleared, and the VM flag is unaffected. The
interrupt flag (IF) is altered only when executing at a level at least as
privileged as the IOPL. If a POPF/POPFD instruction is executed with
insufficient privilege, an exception does not occur, but the privileged bits
do not change. |
||||||||||||||||||||||||
|
por |
Bitwise Logical OR SSE/SSE2
Instruction MMX
Instruction |
|
Performs a
bitwise logical OR operation on the source operand (first operand) and the
destination operand (second operand) and stores the result in the destination
operand. The source operand can be an MMX register or a 64-bit memory
location or it can be an XMM register or a 128-bit memory location. The
destination operand can be an MMX register or an XMM register. Each bit of
the result is set to 1 if either or both of the corresponding bits of the
first and second operands are 1; otherwise, it is set to 0. |
||||||||||||||||||||||||
|
psadbw |
Compute Sum of Absolute Differences. SSE/SSE2
Instruction MMX
Instruction |
|
Computes the absolute
value of the difference of 8 unsigned byte integers from the source operand
(second operand) and from the destination operand (first operand). These 8
differences are then summed to produce an unsigned word integer result that
is stored in the destination operand. The source operand can be an MMX
register or a 64-bit memory location or it can be an XMM register or a
128-bit memory location. The destination operand can be an MMX register or an
XMM register. When
operating on 64-bit operands, the word integer result is stored in the low
word of the destination operand, and the remaining bytes in the destination
operand are cleared to all 0s. When operating on 128-bit operands, two packed
results are computed. Here, the 8 low-order bytes of the source and
destination operands are operated on to produce a word result that is stored
in the low word of the destination operand, and the 8 high-order bytes are
operated on to produce a word result that is stored in bits 64 through 79 of
the destination operand. The remaining bytes of the destination operand are
cleared to 0s. |
||||||||||||||||||||||||
|
pshufd |
Shuffle Packed Double words. SSE/SSE2
Instruction MMX
Instruction |
|
Copies double words
from source operand (first operand) and inserts them in the destination
operand (second operand) at locations selected with the order operand (third
operand). The figure shows the operation of the PSHUFD instruction and the
encoding of the order operand. Each 2-bit field in the order operand selects
the contents of one double word location in the destination operand. For
example, bits 0 and 1 of the order operand selects the contents of double
word 0 of the destination operand. The encoding of bits 0 and 1 of the order
operand (see the field encoding in figure) determines which double word from
the source operand will be copied to double-word 0 of the destination
operand.
The source operand can
be an XMM register or a 128-bit memory location. The destination operand is
an XMM register. The order operand is an 8-bit immediate. Note that this
instruction permits a double word in the source operand to be copied to more
than one double word location in the destination operand. |
||||||||||||||||||||||||
|
pshufhw |
Shuffle Packed High Words. SSE/SSE2
Instruction MMX
Instruction |
|
Copies words from the
high quad word of the source operand (first operand) and inserts them in the
high quad word of the destination operand (second operand) at word locations
selected with the order operand (third operand). This operation is similar to
the operation used by the PSHUFD instruction, which is illustrated in the
figure. For the PSHUFHW instruction, each 2-bit field in the order operand
selects the contents of one word location in the high quad word of the
destination operand. The binary encoding of the order operand fields select
words (0, 1, 2, or 3 4) from the high quad word of the source operand to be
copied to the destination operand. The source operand can be an XMM register
or a 128-bit memory location. The destination operand is an XMM register. The
order operand is an 8-bit immediate. Note that this instruction permits a
word in the source operand to be copied to more than one word location in the
destination operand. |
||||||||||||||||||||||||
|
pshuflw |
Shuffle Packed Low Words. SSE/SSE2
Instruction MMX
Instruction |
|
See pshufhw. |
||||||||||||||||||||||||
|
pshufw |
Shuffle Packed Words. MMX Instruction |
|
Copies words from the
source operand (first operand) and inserts them in the destination operand (second
operand) at word locations selected with the order operand (third operand).
This operation is similar to the operation used by the PSHUFD instruction,
which is illustrated in Figure 3-10. For the PSHUFW instruction, each 2-bit
field in the order operand selects the contents of one word location in the
destination operand. The encodings of the order operand fields select words
from the source operand to be copied to the destination operand. The source operand can
be an MMX register or a 64-bit memory location. The destination operand is an MMX
register. The order operand is an 8-bit immediate. Note that this
instruction permits a word in the source operand to be copied to more than
one word location in the destination operand. |
||||||||||||||||||||||||
|
pslldq |
Shift Double Quad word Left Logical. SSE/SSE2
Instruction |
|
Shifts the destination
operand (second operand) to the left by the number of bytes specified in the
count operand (first operand). The empty low-order bytes are cleared (set to
all 0s). If the value specified by the count operand is greater than 15, the
destination operand is set to all 0s. The destination
operand is an XMM register. The count operand is an 8-bit immediate. |
||||||||||||||||||||||||
|
psllw |
Shift Packed Data Left Logical. SSE/SSE2
Instruction MMX
Instruction |
|
Shifts the bits in the
individual data elements (words, double words, or quad word) in the
destination operand (second operand) to the left by the number of bits
specified in the count operand (first operand). As the bits in the data
elements are shifted left, the empty low-order bits are cleared (set to 0).
If the value specified by the count operand is greater than 15 (for words),
31 (for double words), or 63 (for a quad word), then the destination operand
is set to all 0s. The destination operand may be an MMX register or an XMM
register; the count operand can be either an MMX register or an 64-bit memory
location, an XMM register or a 128-bit memory location, or an 8-bit
immediate. The PSLLW instruction
shifts each of the words in the destination operand to the left by the number
of bits specified in the count operand; the PSLLD instruction shifts each of
the double-words in the destination operand; and the PSLLQ instruction shifts
the quad word (or quad-words) in the destination operand. |
||||||||||||||||||||||||
|
pslld |
|
||||||||||||||||||||||||||
|
psllq |
|
||||||||||||||||||||||||||
|
psrad |
Shift Packed Data Right Arithmetic. SSE/SSE2
Instruction MMX
Instruction |
|
Shifts the bits in the
individual data elements (words or double words) in the destination operand
(second operand) to the right by the number of bits specified in the count
operand (first operand). As the bits in the
data elements are shifted right, the empty high-order bits are filled with
the initial value of the sign bit of the data element. If the value specified
by the count operand is greater than 15 (for words) or 31 (for double words),
each destination data element is filled with the initial value of the sign
bit of the element. |
||||||||||||||||||||||||
|
psraw |
|
||||||||||||||||||||||||||
|
psrldq |
Shift Double Quad word Right Logical. SSE/SSE2
Instruction |
|
Shifts the destination
operand (first operand) to the right by the number of bytes specified in the
count operand (first operand). The empty high-order bytes are cleared (set to
all 0s). If the value specified by the count operand is greater than 15, the
destination operand is set to all 0s. The destination
operand is an XMM register. The count operand is an 8-bit immediate. |
||||||||||||||||||||||||
|
psrlw |
Shift Packed Data Right Logical. SSE/SSE2
Instruction MMX
Instruction |
|
Shifts the bits in the
individual data elements (words, double words, or quad word) in the
destination operand (second operand) to the right by the number of bits
specified in the count operand (first operand). As the bits in the data
elements are shifted right, the empty high-order bits are cleared (set to 0).
If the value specified by the count operand is greater than 15 (for words),
31 (for double words), or 63 (for a quad word), then the destination operand
is set to all 0s. The destination operand may be an MMX register or an XMM
register; the count operand can be either an MMX register or an 64-bit memory
location, an XMM register or a 128-bit memory location, or an 8-bit
immediate. |
||||||||||||||||||||||||
|
psrld |
|
||||||||||||||||||||||||||
|
psrlq |
|
||||||||||||||||||||||||||
|
psubb |
Subtract Packed Integers. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
subtract of the packed integers of the source operand (first operand) from
the packed integers of the destination operand (second operand), and stores
the packed integer results in the destination operand. Overflow is handled
with wraparound, as described in the following paragraphs. These instructions can
operate on either 64-bit or 128-bit operands. When operating on 64-bit
operands, the destination operand must be an MMX register and the source
operand can be either an MMX register or a 64-bit memory location. When
operating on 128-bit operands, the destination operand must be an XXM
register and the source operand can be either an XMM register or a 128-bit
memory location. The PSUBB instruction
subtracts packed byte integers. When an individual result is too large or too
small to be represented in a byte, the result is wrapped around and the low 8
bits are written to the destination element. The PSUBW instruction
subtracts packed word integers. When an individual result is too large or too
small to be represented in a word, the result is wrapped around and the low
16 bits are written to the destination element. The PSUBD instruction
subtracts packed double word integers. When an individual result is too large
or too small to be represented in a double word, the result is wrapped around
and the low 32 bits are written to the destination element. Note that the PSUBB,
PSUBW, and PSUBD instructions can operate on either unsigned or signed (two's
complement notation) packed integers; however, it does not set bits in the EFLAGS register to
indicate overflow and/or a carry. To prevent undetected overflow conditions,
software must control the ranges of values operated on. |
||||||||||||||||||||||||
|
psubw |
|
||||||||||||||||||||||||||
|
psubd |
|
||||||||||||||||||||||||||
|
psubq |
Subtract Packed Quad word Integers. SSE/SSE2 Instruction |
|
See psubb. |
||||||||||||||||||||||||
|
psubsb |
Subtract Packed Signed Integers with Signed
Saturation. SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
subtract of the packed signed integers of the source operand (first operand)
from the packed signed integers of the destination operand (second operand),
and stores the packed integer results in the destination operand. Overflow is
handled with signed saturation, as described in the following paragraphs. These instructions can
operate on either 64-bit or 128-bit operands. When operating on 64-bit
operands, the destination operand must be an MMX register and the source
operand can be either an MMX register or a 64-bit memory location. When
operating on 128-bit operands, the destination operand must be an XXM
register and the source operand can be either an XMM register or a 128-bit memory
location. The PSUBSB instruction
subtracts packed signed byte integers. When an individual byte result is
beyond the range of a signed byte integer (that is, greater than 7FH or less
than 80H), the saturated value of 7FH or 80H, respectively, is written to the
destination operand. The PSUBSW instruction
subtracts packed signed word integers. When an individual word result is
beyond the range of a signed word integer (that is, greater than 7FFFH or
less than 8000H), the saturated
value of 7FFFH or 8000H, respectively, is written to the destination operand. |
||||||||||||||||||||||||
|
psubsw |
|
||||||||||||||||||||||||||
|
psubusb |
Subtract Packed Unsigned Integers with Unsigned
Saturation SSE/SSE2
Instruction MMX
Instruction |
|
Performs a SIMD
subtract of the packed unsigned integers of the source operand (first operand)
from the packed unsigned integers of the destination operand (second
operand), and stores the packed unsigned integer results in the destination
operand. Overflow is handled
with unsigned saturation, as described in the following paragraphs. These instructions can
operate on either 64-bit or 128-bit operands. When operating on 64-bit
operands, the destination operand must be an MMX register and the source
operand can be either an MMX register or a 64-bit memory location. When
operating on 128-bit operands, the destination operand must be an XXM
register and the source operand can be either an XMM register or a 128-bit
memory location. The PSUBUSB
instruction subtracts packed unsigned byte integers. When an individual byte
result is less than zero, the saturated value of 00H is written to the
destination operand. The PSUBUSW
instruction subtracts packed unsigned word integers. When an individual word
result is less than zero, the saturated value of 0000H is written to the
destination operand. |
||||||||||||||||||||||||
|
psubusw |
|
||||||||||||||||||||||||||
|
punpckhbw |
Unpack High Data SSE/SSE2
Instruction MMX
Instruction |
|
Unpacks and
interleaves the high-order data elements (bytes, words, double words, or
quad-words) of the destination operand (second operand) and source operand
(first operand) into the destination operand. The low-order data elements are
ignored. The source operand can
be an MMX register or a 64-bit memory location, or it can be an XMM register
or a 128-bit memory location. The destination operand can be an MMX or an XMM
register. When the source data comes from a 64-bit memory operand, the full
64-bit operand is accessed from memory, but the instruction uses only the
high-order 32 bits. When the source data comes from a 128-bit memory operand,
a processor implementation may fetch only the appropriate 64 bits from
memory. Alignment to 16-byte boundary and normal segment checking will still
be enforced. |
||||||||||||||||||||||||
|
punpckhwd |
|
||||||||||||||||||||||||||
|
punpckhdq |
|
||||||||||||||||||||||||||
|
punpckhqdq |
|
||||||||||||||||||||||||||
|
punpcklbw |
Unpack Low Data. SSE/SSE2
Instruction MMX
Instruction |
|
Unpacks and
interleaves the low-order data elements (bytes, words, double words, and
quad-words) of the destination operand (second operand) and source operand
(first operand) into the destination operand.. The high-order data elements
are ignored. The source operand can
be an MMX register or a 64-bit memory location, or it can be an XMM register
or a 128-bit memory location. The destination operand can be an MMX or an XMM
register. When the source data comes from a 64-bit memory operand, the full
64-bit operand is accessed from memory, but the instruction uses only the
high-order 32 bits. When the source data comes from a 128-bit memory operand,
a processor implementation may fetch only the appropriate 64 bits from
memory. Alignment to 16-byte boundary and normal segment checking will still
be enforced. |
||||||||||||||||||||||||
|
punpcklwd |
|
||||||||||||||||||||||||||
|
punpckldq |
|
||||||||||||||||||||||||||
|
punpcklqdq |
|
||||||||||||||||||||||||||
|
prefetch |
Prefetch Data Into Caches |
|
Fetches the line of
data from memory that contains the byte specified with the source operand to
a location in the cache hierarchy specified by a locality hint: • T0 (temporal
data)—prefetch data into all cache levels. • T1 (temporal data with
respect to first level cache)—prefetch data in all cache levels except 0th
cache level • T2 (temporal data with
respect to second level cache)—prefetch data in all cache levels, except 0th
and 1st cache levels. • NTA (non-temporal data
with respect to all cache levels)—prefetch data into non-temporal cache
structure. (This hint can be used to minimize pollution of caches.) The source operand is
a byte memory location. (The locality hints are encoded into the machine
level instruction using bits 3 through 5 of the ModR/M byte. Use of any
ModR/M value other than the specified ones will lead to unpredictable
behavior.) If the line selected
is already present in the cache hierarchy at a level closer to the processor,
no data movement occurs. Prefetches from uncacheable or WC memory are
ignored. The PREFETCHh instruction is merely
a hint and does not affect program behavior. If executed, this instruction
moves data closer to the processor in anticipation of future use. The implementation of
prefetch locality hints is implementation-dependent, and can be over-loaded
or ignored by a processor implementation. The amount of data prefetched is
also processor implementation-dependent. It will, however, be a minimum of 32
bytes. It should be noted
that processors are free to speculatively fetch and cache data from system
memory regions that are assigned a memory-type that permits speculative reads
(that is, the WB, WC, and WT memory types). A PREFETCHh instruction is
considered a hint to this speculative behavior. Because this speculative
fetching can occur at any time and is not tied to instruction execution, a
PREFETCHh
instruction
is not ordered with respect to the fence instructions (MFENCE, SFENCE, and
LFENCE) or locked memory references. A PREFETCHh instruction is also
unordered with respect to CLFLUSH instructions, other PREFETCHh instructions, or any other
general instruction. It is ordered with respect to serializing instructions
such as CPUID, WRMSR, and OUT, and MOV CR. |
||||||||||||||||||||||||
|
prefetchw |
|
||||||||||||||||||||||||||
|
push |
Push Word or Double word Onto the Stack |
|
Decrements the stack
pointer and then stores the source operand on the top of the stack. The
address-size attribute of the stack segment determines the stack pointer size
(16 bits or 32 bits), and the operand-size attribute of the current code
segment determines the amount the stack pointer is decremented (2 bytes or 4
bytes). For example, if these address- and operand-size attributes are 32,
the 32-bit ESP register (stack pointer) is decremented by 4 and, if they are
16, the 16-bit SP register is decremented by 2. (The B flag in the stack
segment’s segment descriptor determines the stack’s address-size attribute,
and the D flag in the current code segment’s segment descriptor, along with
prefixes, determines the operand-size attribute and also the address-size
attribute of the source operand.) Pushing a 16-bit operand when the stack
address-size attribute is 32 can result in a misaligned the stack pointer
(that is, the stack pointer is not aligned on a double word boundary). The PUSH ESP
instruction pushes the value of the ESP register as it existed before the
instruction was executed. Thus, if a PUSH instruction uses a memory operand
in which the ESP register is used as a base register for computing the
operand address, the effective address of the operand is computed before the
ESP register is decremented. In the real-address mode, if the ESP or SP
register is 1 when the PUSH instruction is executed, the
processor shuts down due to a lack of stack space. No exception is generated
to indicate this condition. |
||||||||||||||||||||||||
|
pusha |
Push All General-Purpose Registers |
|
Pushes the contents of
the general-purpose registers onto the stack. The registers are stored on the
stack in the following order: EAX, ECX, EDX, EBX, EBP, ESP (original value),
EBP, ESI, and EDI (if the current operand-size attribute is 32) and AX, CX,
DX, BX, SP (original value), BP, SI, and DI (if the operand-size attribute is
16). These instructions perform the reverse operation of the POPA/POPAD
instructions. The value pushed for the ESP or SP register is its value before
prior to pushing the first register. The PUSHA (push all)
and PUSHAD (push all double) mnemonics reference the same opcode. The PUSHA
instruction is intended for use when the operand-size attribute is 16 and the
PUSHAD instruction for when the operand-size attribute is 32. Some assemblers
may force the operand size to 16 when PUSHA is used and to 32 when PUSHAD is
used. Others may treat these mnemonics as synonyms (PUSHA/PUSHAD) and use the
current setting of the operand-size attribute to determine the size of values
to be pushed from the stack, regardless of the mnemonic used. In the
real-address mode, if the ESP or SP register is 1, 3, or 5 when the PUSHA/PUSHAD
instruction is executed, the processor shuts down due to a lack of stack
space. No exception is generated to indicate this condition. |
||||||||||||||||||||||||
|
pushf |
Push EFLAGS Register onto the Stack |
|
Decrements the stack
pointer by 4 (if the current operand-size attribute is 32) and pushes the
entire contents of the EFLAGS register onto the stack, or decrements the
stack pointer by 2 (if the operand-size attribute is 16) and pushes the lower
16 bits of the EFLAGS register (that is, the FLAGS register) onto the stack.
(These instructions reverse the operation of the POPF/POPFD
instructions.) When copying the entire EFLAGS register to the stack, the VM
and RF flags (bits 16 and 17) are not copied; instead, the values for these
flags are cleared in the EFLAGS image stored on the stack.. The PUSHF (push flags)
and PUSHFD (push flags double) mnemonics reference the same opcode. The PUSHF
instruction is intended for use when the operand-size attribute is 16 and the
PUSHFD instruction for when the operand-size attribute is 32. Some assemblers
may force the operand size to 16 when PUSHF is used and to 32 when PUSHFD is
used. Others may treat these mnemonics as synonyms (PUSHF/PUSHFD) and use the
current setting of the operand-size attribute to determine the size of values
to be pushed from the stack, regardless of the mnemonic used. When in
virtual-8086 mode and the I/O privilege level (IOPL) is less than 3, the
PUSHF/PUSHFD instruction causes a general protection exception (#GP). In the
real-address mode, if the ESP or SP register is 1, 3, or 5 when the
PUSHA/PUSHAD instruction is executed, the processor shuts down due to a lack
of stack space. No exception is generated to indicate this condition. |
||||||||||||||||||||||||
|
pxor |
Logical Exclusive OR. SSE/SSE2 Instruction MMX Instruction |
|
Performs a
bitwise logical exclusive-OR (XOR) operation on the source operand (first
operand) and the destination operand (second operand) and stores the result
in the destination operand. The source operand can be an MMX register or a
64-bit memory location or it can be an XMM register or a 128-bit memory
location. The destination operand can be an MMX register or an XMM register.
Each bit of the result is 1 if the corresponding bits of the two operands are
different; each bit is 0 if the corresponding bits of the operands are the
same. |
||||||||||||||||||||||||
|
rcl |
Rotate |
|
Shifts (rotates) the
bits of the second operand (destination operand) the number of bit positions
specified in the first operand (count operand) and stores the result in the
destination operand. The destination
operand can be a register or a memory location; the count operand is an
unsigned integer that can be an immediate or a value in the CL register. The
processor restricts the count to a number between 0 and 31 by masking all the
bits in the count operand except the 5 least-significant bits. The rotate left (ROL)
and rotate through carry left (RCL) instructions shift all the bits toward
more-significant bit positions, except for the most-significant bit, which is
rotated to the least-significant bit location. The rotate right (ROR) and
rotate through carry right (RCR) instructions shift all the bits toward less
significant bit positions, except for the least-significant bit, which is
rotated to the most-significant bit location. The RCL and RCR
instructions include the CF flag in the rotation. The RCL instruction shifts
the CF flag into the least-significant bit and shifts the most-significant
bit into the CF flag. The RCR instruction shifts the CF flag into the
most-significant bit and shifts the least-significant bit into the CF flag.
For the ROL and ROR instructions, the original value of the CF flag is not a
part of the result, but the CF flag receives a copy of the bit that was
shifted from one end to the other. The OF flag is defined only for the 1-bit
rotates; it is undefined in all other cases (except that a zero-bit rotate
does nothing, that is affects no flags). For left rotates, the OF flag is set
to the exclusive
OR of the CF bit (after the rotate) and the most-significant bit of the
result. For right rotates, the OF flag is set to the exclusive OR of the two
most-significant bits of the result. |
||||||||||||||||||||||||
|
rcr |
|
||||||||||||||||||||||||||
|
rcpps |
Compute Reciprocals of Packed Single-Precision
Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a SIMD
computation of the approximate reciprocals of the four packed single
precision floating-point values in the source operand (first operand) stores
the packed single-precision floating-point results in the destination
operand. The maximum relative error for this approximation is (1.5 *2
-12 ). The source operand
can be an XMM register or a 128-bit memory location. The destination operand
is an XMM register. The RCPSS instruction
is not affected by the rounding control bits in the MXCSR register. When a source value is
a 0.0, an 8of the sign of the
source value is returned. A denormal source value is treated as a 0.0 (of the
same sign). Underflow results are always flushed to 0.0, with the sign of the
operand. When a source value is an SNaN or QNaN, the SNaN converted to a QNaN
or the source QNaN is returned. |
||||||||||||||||||||||||
|
rcpss |
Compute Reciprocal of Scalar Single-Precision
Floating-Point Values. SSE/SSE2
Instruction |
|
See rcpps |
||||||||||||||||||||||||
|
rdpmc |
Read Performance-Monitoring Counters |
|
Loads the contents of
the 40-bit performance-monitoring counter specified in the ECX register into
registers EDX:EAX. The EDX register is loaded with the high-order 8 bits of
the counter and the EAX register is loaded with the low-order 32 bits. The
counter to be read is specified with an unsigned integer placed in the ECX
register. The P6 processors have two performance-monitoring counters (0 and
1), which are specified by placing 0000H or 0001H, respectively, in the ECX
register. The Pentium 4 processors have 18 counters (0 through 17), which are
specified with 0000H through
0011H, respectively The Pentium 4 processors also support “fast” (32-bit) and
“slow” (40-bit) reads of the performance counters, selected with bit 31 of
the ECX register. If bit 31 is set, the RDPMC instruction reads only the low
32 bits of the selected performance counter; if bit 31 is clear, all 40 bits
of the counter are read. The 32-bit counter result is returned in the EAX
register, and the EDX register is set to 0. A 32-bit
read executes faster on a Pentium 4 processor than a full 40-bit read. The
RDPMC instruction allows application code running at a privilege level of 1,
2, or 3 to read the performance monitoring counters if the PCE flag in the
CR4 register is set. This instruction is provided to allow performance
monitoring by application code without incurring the overhead of a call to an
operating-system procedure. The
performance-monitoring counters are event counters that can be programmed to
count events such as the number of instructions decoded, number of interrupts
received, or number of cache loads. Appendix A, Performance-Monitoring
Events,
in the IA-32
Intel Architecture Soft-ware Developer’s
Manual, Volume 3,
lists the events that can be counted for the Pentium 4 earlier IA-32
processors. The RDPMC instruction
is not a serialize instruction; that is, it does not imply that all the
events caused by the preceding instructions have been completed or that
events caused by subsequent instructions have not begun. If an exact event
count is desired, software must insert a serializing instruction (such as
the CPUID instruction) before and/or after the RDPCM instruction. In the
Pentium 4 processors, performing back-to-back fast reads are not guaranteed
to be mono-tonic. To guarantee monotonicity on back-to-back reads, a
serializing instruction must be placed between the tow RDPMC instructions.
The RDPMC instruction can execute in 16-bit addressing mode or virtual-8086
mode; however, the full contents of the ECX register are used to select the
counter, and the event count is stored in the full
EAX and EDX registers. |
||||||||||||||||||||||||
|
rdtsc |
Read Time-Stamp Counter |
|
Loads the current
value of the processor’s time-stamp counter into the EDX:EAX registers. The
time-stamp counter is contained in a 64-bit MSR. The high-order 32 bits of
the MSR are loaded into the EDX register, and the low-order 32 bits are
loaded into the EAX register. The processor increments the time-stamp counter
MSR every clock cycle and resets it to 0 whenever the processor is reset. The time stamp disable
(TSD) flag in register CR4 restricts the use of the RDTSC instruction. When
the TSD flag is clear, the RDTSC instruction can be executed at any privilege
level; when the flag is set, the instruction can only be executed at
privilege level 0. The time-stamp counter can also be read with the RDMSR
instruction, when executing at privilege level 0. The RDTSC
instruction is not a serializing instruction. Thus, it does not necessarily
wait until all previous instructions have been executed before reading the
counter. Similarly, subsequent instructions may begin execution before the
read operation is performed. This instruction was introduced into the IA-32
Architecture in the Pentium processor. |
||||||||||||||||||||||||
|
ret |
Return from Procedure |
|
Transfers program
control to a return address located on the top of the stack. The address is
usually placed on the stack by a CALL instruction, and the return is made to
the instruction that follows the CALL instruction. The optional source
operand specifies the number of stack bytes to be released after the return
address is popped; the default is none. This operand can be used to release
parameters from the stack that were passed to the called procedure and are no
longer needed. It must be used when the CALL instruction
used to switch to a new procedure uses a call gate with a non-zero word count
to access the new procedure. Here, the source operand for the RET instruction
must specify the same number of bytes as is specified in the word count field
of the call gate. The RET instruction
can be used to execute three different types of returns: • Near return—A return
to a calling procedure within the current code segment (the segment currently
pointed to by the CS register), sometimes referred to as an intrasegment
return. • Far return—A return to
a calling procedure located in a different segment than the current code
segment, sometimes referred to as an intersegment return. • Inter-privilege-level
far return—A far return to a different privilege level than that of the
currently executing program or procedure. The
inter-privilege-level return type can only be executed in protected mode.. When
executing a near return, the processor pops the return instruction pointer
(offset) from the top of the stack into the EIP register and begins program
execution at the new instruction pointer. The CS register is unchanged. When
executing a far return, the processor pops the return instruction pointer
from the top of the stack into the EIP register, then pops the segment
selector from the top of the stack into the CS register. The processor then
begins program execution in the new code segment at the new instruction
pointer. |
||||||||||||||||||||||||
|
rol |
Rotate |
|
See RCL |
||||||||||||||||||||||||
|
ror |
|
||||||||||||||||||||||||||
|
rsqrtps |
Compute Reciprocals of Square Roots of Packed
Single-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs a SIMD
computation of the approximate reciprocals of the square roots of the four
packed single-precision floating-point values in the source operand (first
operand) and stores the packed single-precision floating-point results in the
destination operand. The maximum relative error for this approximation is (1.5 *2
-12 ). The source operand
can be an XMM register or a 128-bit memory location. The destination operand
is an XMM register. The RSQRTPS
instruction is not affected by the rounding control bits in the MXCSR
register. When a
source value is a 0.0, an 8of the sign of the source value is
returned. A denormal source value is treated as a 0.0 (of the same sign).
When a source value is a negative value (other than -0.0),
a floating-point indefinite is returned. Underflow results are always flushed
to 0.0, with the sign of the operand. When a source value is an SNaN or QNaN,
the SNaN converted to a QNaN or the source QNaN is returned. |
||||||||||||||||||||||||
|
rsqrtss |
Compute Reciprocal of Square Root of Scalar
Single-Precision Floating-Point Value. SSE/SSE2
Instruction |
|
See rsqrtps. |
||||||||||||||||||||||||
|
sahf |
Store AH into Flags |
|
Loads the
SF, ZF, AF, PF, and CF flags of the EFLAGS register with values from the
corresponding bits in the AH register (bits 7, 6, 4, 2, and 0, respectively).
Bits 1, 3, and 5 of register AH are ignored; the corresponding reserved bits
(1, 3, and 5) in the EFLAGS register are: EFLAGS(SF:ZF:0:AF:0:PF:1:CF)
.AH; |
||||||||||||||||||||||||
|
sal |
Shift |
|
Shifts the bits in the
second operand (destination operand) to the left or right by the number of
bits specified in the first operand (count operand). Bits shifted beyond the
destination operand boundary are first shifted into the CF flag, and then
discarded. At the end of the shift operation, the CF flag contains the last
bit shifted out of the destination operand. The destination operand can be a
register or a memory location. The count operand can be an immediate value or
register CL. The count is masked to 5 bits, which limits the count range to 0
to 31. A special opcode encoding is provided for a count of 1. The shift arithmetic
left (SAL) and shift logical left (SHL) instructions perform the same
operation; they shift the bits in the destination operand to the left (toward
more significant bit locations). For each shift count, the most significant
bit of the destination operand is shifted into the CF flag, and the least
significant bit is cleared. The shift arithmetic
right (SAR) and shift logical right (SHR) instructions shift the bits of the
destination operand to the right (toward less significant bit locations). For
each shift count, the least significant bit of the destination operand is
shifted into the CF flag, and the most significant bit is either set or
cleared depending on the instruction type. The SHR instruction clears the
most significant bit; the SAR instruction sets or clears the most significant
bit to correspond to the sign (most significant bit) of the original value in
the destination operand. In effect, the SAR instruction fills the empty bit
position’s shifted value with the sign of the unshifted value. The SAR and SHR
instructions can be used to perform signed or unsigned division,
respectively, of the destination operand by powers of 2. For example, using
the SAR instruction to shift a signed integer 1 bit to the right divides the
value by 2. Using the SAR
instruction to perform a division operation does not produce the same result
as the IDIV instruction. The quotient from the IDIV instruction is rounded
toward zero, whereas the “quotient” of the SAR instruction is rounded toward
negative infinity. This difference is apparent only for negative numbers. For
example, when the IDIV instruction is used to divide -9 by 4, the result is
-2 with a remainder of -1. If the SAR instruction is used to shift -9 right
by two bits, the result is -3 and the “remainder” is +3; however, the SAR
instruction stores only the most significant bit of the remainder (in the CF
flag). The OF flag
is affected only on 1-bit shifts. For left shifts, the OF flag is cleared to
0 if the most-significant bit of the result is the same as the CF flag (that
is, the top two bits of the original operand were the same); otherwise, it is
set to 1. For the SAR instruction, the OF flag is cleared for all 1-bit
shifts. For the SHR instruction, the OF flag is set to the most-significant
bit of the original operand. |
||||||||||||||||||||||||
|
sar |
|
||||||||||||||||||||||||||
|
sbb |
Integer Subtraction with Borrow |
|
Adds the source operand
(first operand) and the carry (CF) flag, and subtracts the result from the
destination operand (second operand). The result of the subtraction is stored
in the destination operand. The destination operand can be a register or a
memory location; the source operand can be an immediate, a register, or a
memory location. (However, two memory operands cannot be used in one
instruction.) The state of the CF flag represents a borrow from a previous
subtraction. When an immediate value is used as an operand, it is
sign-extended to the length of the destination operand format. The SBB instruction
does not distinguish between signed or unsigned operands. Instead, the
processor evaluates the result for both data types and sets the OF and CF
flags to indicate a borrow in the signed or unsigned result, respectively.
The SF flag indicates the sign of the signed result. The SBB instruction is
usually executed as part of a multibyte or multiword subtraction in which a
SUB instruction is followed by a SBB instruction. This
instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically. |
||||||||||||||||||||||||
|
scas |
|
|
|
||||||||||||||||||||||||
|
seta |
Set
byte if above (CF=0 and ZF=0) |
|
Set the destination operand
to 0 or 1 depending on the settings of the status flags (CF, SF, OF, ZF, and
PF) in the EFLAGS register. The destination operand points to a byte register
or a byte in memory. The condition code suffix (cc) indicates the
condition being tested for. The terms “above” and “below” are associated with
the CF flag and refer to the relationship between two unsigned integer
values. The terms “greater” and “less” are associated with the SF and OF
flags and refer to the relationship between two signed integer values. Many
of the SETcc
instruction
opcodes have alternate mnemonics. For example, SETG (set byte if greater) and
SETNLE (set if not less or equal) have the same opcode and test for the same
condition: ZF equals 0 and SF equals OF. These alternate mnemonics are
provided to make code more intelligible. Some
languages represent a logical one as an integer with all bits set. This
representation can be obtained by choosing the logically opposite condition
for the SETcc instruction, then decrementing the result.
For example, to test for overflow, use the SETNO instruction, and then
decrement the result. |
||||||||||||||||||||||||
|
setae |
Set
byte if above or equal (CF=0) |
|
|||||||||||||||||||||||||
|
setb |
Set
byte if below (CF=1) |
|
|||||||||||||||||||||||||
|
setbe |
Set
byte if below or equal (CF=1 or ZF=1) |
|
|||||||||||||||||||||||||
|
sete |
Set byte
if equal (ZF=1) |
|
|||||||||||||||||||||||||
|
setg |
Set
byte if greater (ZF=0 and SF=OF) |
|
|||||||||||||||||||||||||
|
setge |
Set
byte if greater or equal (SF=OF) |
|
|||||||||||||||||||||||||
|
setl |
Set
byte if less (SF<>OF) |
|
|||||||||||||||||||||||||
|
setle |
Set
byte if less or equal (ZF=1 or SF<>OF) |
|
|||||||||||||||||||||||||
|
setna |
Set byte
if not above (CF=1 or ZF=1) |
|
|||||||||||||||||||||||||
|
setnae |
Set
byte if not above or equal (CF=1) |
|
|||||||||||||||||||||||||
|
setnb |
Set
byte if not below (CF=0) |
|
|||||||||||||||||||||||||
|
setnbe |
Set
byte if not below or equal (CF=0 and ZF=0) |
|
|||||||||||||||||||||||||
|
setne |
Set
byte if not carry (CF=0) |
|
|||||||||||||||||||||||||
|
setng |
Set byte
if not greater (ZF=1 or SF<>OF) |
|
|||||||||||||||||||||||||
|
setnge |
Set
if not greater or equal (SF<>OF) |
|
|||||||||||||||||||||||||
|
setnl |
Set
byte if not less (SF=OF) |
|
|||||||||||||||||||||||||
|
setnle |
Set
byte if not less or equal (ZF=0 and SF=OF) |
|
|||||||||||||||||||||||||
|
setno |
Set
byte if not overflow (OF=0) |
|
|||||||||||||||||||||||||
|
setnp |
Set byte
if not parity (PF=0) |
|
|||||||||||||||||||||||||
|
setns |
Set
byte if not sign (SF=0) |
|
|||||||||||||||||||||||||
|
setnz |
Set
byte if not zero (ZF=0) |
|
|||||||||||||||||||||||||
|
seto |
Set
byte if overflow (OF=1) |
|
|||||||||||||||||||||||||
|
setp |
Set
byte if parity (PF=1) |
|
|||||||||||||||||||||||||
|
setpe |
Set
byte if parity even (PF=1) |
|
|||||||||||||||||||||||||
|
setpo |
Set byte
if parity odd (PF=0) |
|
|||||||||||||||||||||||||
|
sets |
Set
byte if sign (SF=1) |
|
|||||||||||||||||||||||||
|
setz |
Set
byte if zero (ZF=1) |
|
|||||||||||||||||||||||||
|
sgdt |
Store Global/Interrupt Descriptor Table Register |
|
Stores the
contents of the global descriptor table register (GDTR) or the interrupt descriptor
table register (IDTR) in the destination operand. The destination operand
specifies a 6-byte memory location. If the operand-size attribute is 32 bits,
the 16-bit limit field of the register is stored in the lower 2 bytes of the
memory location and the 32-bit base address is stored in the upper 4 bytes.
If the operand-size attribute is 16 bits, the limit is stored in the lower 2
bytes and the 24-bit base address is stored in the third, fourth, and fifth
byte, with the sixth byte filled with 0s. The SGDT and SIDT instructions are
only useful in operating-system software; however, they can be used in
application programs without causing an exception to be generated. |
||||||||||||||||||||||||
|
shl |
Shift Instructions |
|
See SAL. |
||||||||||||||||||||||||
|
shld |
|
||||||||||||||||||||||||||
|
shr |
|
||||||||||||||||||||||||||
|
shrd |
|
||||||||||||||||||||||||||
|
shufpd |
Shuffle Packed Double-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Moves
either of the two packed double-precision floating-point values from
destination operand (second operand) into the low quad word of the
destination operand; moves either of the two packed double-precision
floating-point values from the source operand into to the high quad word of
the destination operand. The select operand (third operand) determines which
values are moved to the destination operand. The source
operand can be an XXM register or a 128-bit memory location. The destination
operand is an XMM register. The select operand is an 8-bit immediate: bit 0
selects which value is moved from the destination operand to the result
(where 0 selects the low quadword and 1 selects the high quadword) and bit 1
selects which value is moved from the source operand to the result. Bits 3
through 7 of the shuffle operand are reserved. |
||||||||||||||||||||||||
|
shufps |
Shuffle Packed Single-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
|
||||||||||||||||||||||||
|
sidt |
|
|
|
||||||||||||||||||||||||
|
sldt |
|
|
|
||||||||||||||||||||||||
|
smsw |
|
|
|
||||||||||||||||||||||||
|
sqrtpd |
Compute Square Roots of Packed Double-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Performs a
SIMD computation of the square roots of the two packed double-precision floating-point
values in the source operand (first operand) stores the packed
double-precision floating-point results in the destination operand. The
source operand can be an XMM register or a 128-bit memory location. The
destination operand is an XMM register. |
||||||||||||||||||||||||
|
sqrtps |
Compute Square Roots of Packed Single-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
See sqrtpd. |
||||||||||||||||||||||||
|
sqrtsd |
Compute Square Root of Scalar Double-Precision Floating-Point
Value. SSE/SSE2
Instruction |
|
Computes the
square root of the low double-precision floating-point value in the source
operand (first operand) and stores the double-precision floating-point result
in the destination operand. The source operand can be an XMM register or a
64-bit memory location. The destination operand is an XMM register. The high
quadword of the destination operand remains unchanged. |
||||||||||||||||||||||||
|
sqrtss |
Compute Square Root of Scalar Single-Precision Floating-Point
Value. SSE/SSE2
Instruction |
|
See sqrtsd. |
||||||||||||||||||||||||
|
stc |
Set Carry Flag |
|
Sets the CF
flag in the EFLAGS register. |
||||||||||||||||||||||||
|
std |
Set Direction Flag |
|
Sets the DF
flag in the EFLAGS register. When the DF flag is set to 1, string operations
decrement the index registers (ESI and/or EDI). |
||||||||||||||||||||||||
|
sti |
Set Interrupt Flag |
|
|
||||||||||||||||||||||||
|
stmxscr |
Store MXCSR Register State. SSE/SSE2
Instruction |
|
Stores the
contents of the MXCSR control and status register to the destination operand.
The destination operand is a 32-bit memory location. The reserved bits in the
MXCSR register are stored as 0s. |
||||||||||||||||||||||||
|
stos |
|
|
|
||||||||||||||||||||||||
|
str |
Store Task Register |
|
|
||||||||||||||||||||||||
|
sub |
Subtract |
|
Subtracts the first
operand (source operand) from the second operand (destination operand) and
stores the result in the destination operand. The destination operand can be
a register or a memory location; the source operand can be an immediate,
register, or memory location. (However, two memory operands cannot be used in
one instruction.) When an immediate value is used as an operand, it is
sign-extended to the length of the destination operand format. The SUB
instruction performs integer subtraction. It evaluates the result for both
signed and unsigned integer operands and sets the OF and CF flags to indicate
a borrow in the signed or unsigned result, respectively. The SF flag
indicates the sign of the signed result. This instruction can be used with a
LOCK prefix to allow the instruction to be executed atomically. |
||||||||||||||||||||||||
|
subpd |
Subtract Packed Double-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Performs a SIMD subtract
of the two packed double-precision floating-point values in the source operand (first
operand) from the two packed double-precision floating-point values in the
destination operand (second operand), and stores the packed double-precision
floating-point results in the destination operand. The source operand can be
an XMM register or a 128-bit memory location. The destination operand is an
XMM register. |
||||||||||||||||||||||||
|
subps |
Subtract Packed Single-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
See subpd. |
||||||||||||||||||||||||
|
subsd |
Subtract Scalar Double-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
Subtracts the low
double-precision floating-point value in the source operand (first operand)
from the low double-precision floating-point value in the destination operand
(second operand), and stores the double-precision floating-point result in
the destination operand. The source operand can be an XMM register or a
64-bit memory location. The destination operand is an XMM register. The high
quad word of the destination operand remains unchanged. |
||||||||||||||||||||||||
|
subss |
Subtract Scalar Single-Precision Floating-Point
Values. SSE/SSE2
Instruction |
|
See subsd. |
||||||||||||||||||||||||
|
test |
Logical Compare |
|
Computes
the bit-wise logical AND of second operand (source 1 operand) and the first
operand (source 2 operand) and sets the SF, ZF, and PF status flags according
to the result. The result is then discarded. |
||||||||||||||||||||||||
|
ucomisd |
Unordered Compare Scalar Double-Precision Floating-Point Values and Set EFLAGS. SSE/SSE2
Instruction |
|
Performs and unordered
compare of the double-precision floating-point values in the low quad-words
of source operand 1 (second operand) and source operand 2 (first operand),
and sets the ZF, PF, and CF flags in the EFLAGS register according to the
result (unordered, greater than, less than, or equal). The OF, SF and AF
flags in the EFLAGS register are set to 0. The unordered result is returned
if either source operand is a NaN (QNaN or SNaN). Source operand 1 is an
XMM register; source operand 2 can be an XMM register or a 64 bit memory
location. The UCOMISD
instruction differs from the COMISD instruction in that it signals a SIMD floating-point invalid
operation exception (#I) only when a source operand is an SNaN. The COMISD
instruction signals an invalid operation exception if a source operand is
either a QNaN or an SNaN. The EFLAGS register is not updated if an unmasked
SIMD floating-point exception is generated. |
||||||||||||||||||||||||
|
ucomiss |
Unordered Compare Scalar Single-Precision Floating-Point Values and Set EFLAGS. SSE/SSE2
Instruction |
|
Performs and unordered
compare of the single-precision floating-point values in the low double-words
of the source operand 1 (second operand) and the source operand 2 (first
operand), and sets the ZF, PF, and CF flags in the EFLAGS register according
to the result (unordered, greater than, less than, or equal). In The OF, SF
and AF flags in the EFLAGS register are set to 0. The unordered result is
returned if either source operand is a NaN (QNaN or SNaN). Source operand 1
is an XMM register; source operand 2 can be an XMM register or a 32 bit
memory location. The UCOMISS
instruction differs from the COMISS instruction in that it signals a SIMD
floating-point invalid operation exception (#I) only when a source operand is
an SNaN. The COMISS instruction
signals an invalid operation exception if a source operand is either a QNaN
or an SNaN. The EFLAGS register is not updated if an unmasked SIMD
floating-point exception is generated. |
||||||||||||||||||||||||
|
unpckhpd |
Unpack and Interleave High Packed Double Precision Floating
Point Values. SSE/SSE2
Instruction |
|
Performs an
interleaved unpack of the high double-precision floating-point values from
the source operand (first
operand) and the destination operand (second operand). The source operand can
be an XMM register or a 128-bit memory location; the destination operand is
an XMM register. When unpacking from a
memory operand, an implementation may fetch only the appropriate 64 bits;
however, alignment to 16-byte boundary and normal segment checking will still
be enforced. |
||||||||||||||||||||||||
|
unpckhps |
Unpack and Interleave High Packed Single Precision Floating
Point Values. SSE/SSE2
Instruction |
|
See unpckhpd. |
||||||||||||||||||||||||
|
unpcklpd |
Unpack and Interleave Low Packed Double-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs an
interleaved unpack of the low double-precision floating-point values from the
source operand (first operand) and the destination operand (second operand).
The source operand can be an XMM register or a 128-bit memory location; the
destination operand is an XMM register. |
||||||||||||||||||||||||
|
unpcklps |
Unpack and Interleave Low Packed Single-Precision Floating-Point Values. SSE/SSE2
Instruction |
|
Performs an interleaved
unpack of the low-order single-precision floating-point values from the
source operand (first operand) and the destination operand (second operand).
The source operand can be an XMM register or a 128-bit memory location; the
destination operand is an XMM register. |
||||||||||||||||||||||||
|
verr |
|
|
|
||||||||||||||||||||||||
|
verw |
|
|
|
||||||||||||||||||||||||
|
wait |
Check
pending unmasked floating-point exceptions. |
|
Causes the
processor to check for and handle pending, unmasked, floating-point
exceptions before proceeding. (FWAIT is an alternate mnemonic for the WAIT). |
||||||||||||||||||||||||
|
xadd |
Exchange and Add |
|
Exchanges the second
operand (destination operand) with the second operand (first operand), then
loads the sum of the two values into the destination operand. The destination
operand can be a register or a memory location; the source operand is a
register. This instruction can be used with a LOCK prefix to allow the
instruction to be executed atomically. IA-32 Architecture
Compatibility IA-32 processors
earlier than the Intel486 processor do not recognize this instruction. If
this instruction is used, you should provide an equivalent code sequence that
runs on earlier processors. |
||||||||||||||||||||||||
|
xchg |
Exchange Register/Memory with Register |
|
Exchanges the contents
of the destination (second) and source (first) operands. The operands can be
two general-purpose registers or a register and a memory location. If a
memory operand is referenced, the processor’s locking protocol is
automatically implemented for the duration of the exchange operation,
regardless of the presence or absence of the LOCK prefix or of the value of
the IOPL. (See the LOCK prefix description in this chapter for more
information on the locking protocol.) This instruction is useful
for implementing semaphores or similar data structures for process
synchronization. The XCHG
instruction can also be used instead of the BSWAP instruction for 16-bit
operands. |
||||||||||||||||||||||||
|
xlat |
Table Look-up Translation |
|
Locates a byte entry
in a table in memory, using the contents of the AL register as a table index,
then copies the contents of the table entry back into the AL register. The
index in the AL register is treated as an unsigned integer. The XLAT and
XLATB instructions get the base address of the table in memory from
either the DS:EBX or the DS:BX registers (depending on the address-size
attribute of the instruction, 32 or 16, respectively). (The DS segment may be
overridden with a segment override prefix.) At the assembly-code
level, two forms of this instruction are allowed: the “explicit-operand” form
and the “no-operand” form. The explicit-operand form (specified with the XLAT
mnemonic) allows the base address of the table to be specified explicitly
with a symbol. This explicit-operands form is provided to allow
documentation; however, note that the documentation provided by
this form can be misleading. That is, the symbol does not have to specify the
correct base address. The base address is always specified by the DS:(E)BX
registers, which must be loaded correctly before the XLAT instruction is
executed. The no-operands form (XLATB) provides a “short form” of the XLAT
instructions. Here also the processor assumes that the DS:(E)BX registers
contain the base address of the table. |
||||||||||||||||||||||||
|
Logical Exclusive OR |
|
Performs a bitwise
exclusive OR (XOR) operation on the destination (second) and source (first)
operands and stores the result in the destination operand location. The
source operand can be an immediate, a register, or a memory location; the
destination operand can be a register or a memory location. (However, two
memory operands cannot be used in one
instruction.) Each bit of the result is 1 if the corresponding bits of
the operands are different; each bit is 0 if the corresponding bits are the
same. This
instruction can be used with a LOCK prefix to allow the instruction to be
executed atomically. |
|||||||||||||||||||||||||
|
xorpd |
Bitwise Logical
XOR for Double-Precision Floating-Point Values |
|
Performs a bitwise
logical exclusive-OR of the two packed double-precision floating-point values from the source
operand (first operand) and the destination operand (second operand), and
stores the result in the destination operand. The source operand can be an
XMM register or a 128-bit memory location. The destination operand is an XMM
register. |

